YOLOv10: Real-Time End-to-End Object Detection, Ao Wang, et al., 2024 를 읽고 요약, 정리한 글입니다.github : https://github.com/THU-MIG/yolov10 ◼️contrbution- 기존 YOLO 아키텍쳐는 NMS에 대한 의존성이 높아 정확도는 향상시키지만 latency를 초래함.- 본 논문은 NMS 없는 YOLO 모델을 만들기 위해 이중 할당 전략을 제안하여 중복 예측 문제를 해결함.- 본 논문은 계산 중복을 줄이기 위해 lightweight classification head, spatial-channel decoupled downsampling, rank-guided block design을 포함한 아키텍쳐를 제안함. ..
YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information, Chien-Yao Wang, et al., 2024 을 읽고 요약, 정리한 글입니다. github : https://github.com/WongKinYiu/yolov9 ◼️ Contribution- 현존하는 심층 신경망 구조를 reversible fuction의 과점에서 이론적으로 분석하고 이러한 프로세스를 통해 이전에는 설명하기 어려웠던 많은 현상들에 대해 설명함.- 이러한 분석을 기반으로 PGI와 auxiliary reversible branch를 설계하고 좋은 결과를 얻음.- PGI는 deep supervision이 아주 깊은 신경망 구조에서만 사용할 수 ..
MvMHAT: Self-supervised Multi-view Multi-Human Association and Tracking, Yiyang Gan, et al., 2021 을 읽고 정리, 요약한 글입니다.github : https://github.com/realgump/MvMHAT?tab=readme-ov-file ◼️ Abstract Multi-view Multi-human association and tracking(MvMHAT)은 각 뷰에서 시간 경과에 따른 사람 그룹을 추적하고 동시에 여러 뷰에서 동일한 사람을 식별하는 것을 목표로 한다. 시간 경과에 따른 사람 연관성만 고려하는 이전의 multiple object tracking(MOT) 및 multi-target multi-camera tr..
Multi-view Tracking Using Weakly Supervised Human Motion Prediction, Martin Engilberge, et al., 2022 을 읽고 정리, 요약한 글입니다. ◼️ Abstract people-tracking에 대한 Multi-view 접근 방식은 혼잡한 장면에서 single-view 접근 방식보다 occlusion을 더 잘 처리할 수 있는 잠재력을 가지고 있는데, 이는 대부분 사람을 먼저 detection한 다음 detection된 부분을 연결(association)하는 tracking-by-detection 패러다임에 의존한다.본 논문에서는 시간 경과에 따른 사람의 움직임을 예측하고 이를 통해 개별 프레임에서 사람의 존재를 추론하는 것이 훨씬 더..
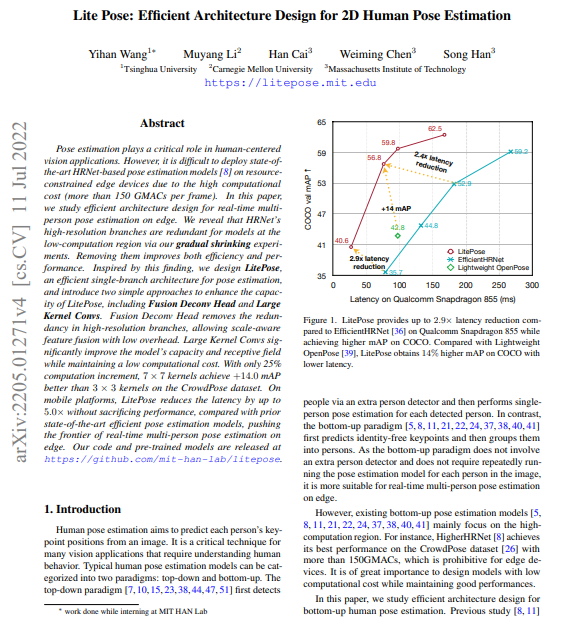
Lite Pose: Efficient Architecture Design for 2D Human Pose Estimation, Yihan Wang et al., 2022 을 읽고 정리, 요약한 글입니다. ▪️ 본 논문의 기여 내용 요약 gradual shrinking 실험을 설계하여 high-resolution branch가 저연산 영역의 모델에 중복된다는 것을 밝힌다. bottom-up pose estimation을 위한 효율적인 아키텍처인 LitePose를 제안한다. 또한 fusion deconv head와 large kernel conv를 포함해 LitePose의 capicity를 향상 시키는 두 가지 기술을 소개한다. Microsoft COCO와 CrowdPose라는 두 가지 benchmark d..
Lite-HRNet: A Lightweight High-Resolution Network, Changqian Yu, Bin Xiao, et al., 2021 을 읽고 정리, 요약한 글입니다. ⏹️ Abstract 본 논문은 human pose estimation을 위한 효율적인 high-resolution network인 LiteHRNet을 제시한다. ShuffleNet의 효율적인 shuffle block을 HRNet(high-resolution network)에 적용하여 MobileNet, ShuffleNet, Small HRNet과 같은 인기 있는 lightweight network보다 더 강력한 성능을 산출하는 것으로 시작한다. shuffle block에서 많이 사용되는 pointwise(1 × 1..
HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation, Bowen Cheng, et al., 2020 논문을 읽고 정리, 요약한 글입니다. ⏹ Abstract Bottom-up human pose estimation은 스케일 변화 문제로 인해 작은 사람의 정확한 포즈를 예측하는 데 어려움이 있다. 본 논문에서는 high-resolution feature pyramid를 사용하여 scale-aware representation을 학습하는 새로운 bottom-up human pose estimation 방법인 HigherHRNet을 소개한다. 학습을 위한 multi-resolution supervision과 추..
Deep High-Resolution Representation Learning for Human Pose Estimation을 읽고 정리, 요약한 글입니다. ⏹️ Abstract 본 논문에서는 신뢰할 수 있는 high-resolution representation을 학습하는 데 중점을 둔 human pose estimation 문제에 관심이 있다. 대부분의 기존 방법은 high-resolution에서 low-resolution 네트워크에 의해 생성된 low resolution에서 high-resolution을 복구한다. 하지만 본 논문에서 제안 된 네트워크는 전체 프로세스를 통해 high-resolution representation을 유지한다. 본 논문은 첫 번째 단계로 high-resolution ..
Self-Supervised Video Transformer(CVPR'22-Oral), Kanchana Ranasinghe, Muzammal Naseer et al.를 읽고 요약&정리 한 글입니다. ⏹ Abstract 본 논문에서는 라벨링이 되지 않은 비디오 데이터를 사용하여 video transformers에 대한 self-supervised training을 제안한다. 주어진 비디오에서 다양한 spatial size와 frame rates로 local 및 global spatio-temporal view를 생성하고 action의 spatio-temporal variations에 불변(invariant)하기 위해 동일한 비디오를 나타내는 다른 특징을 matching시키는 것을 추구한다. 본 논문에서 제..
StrongSORT: Make DeepSORT Great Again, Yunhao Du et al., 2022을 읽고 요약한 글입니다. ⏹️ Abstract 기존의 다중 객체 추적(MOT) 방법은 tracking-by-detection 및 joint-detection-association paradigm으로 분류할 수 있다. 후자가 더 많은 관심을 끌었고 전자에 비해 비슷한 성능을 보여주었지만, 본 논문은 tracking-by-detection paradigm이 여전히 tracking 정확도 측면에서 최적의 솔루션이라고 주장한다. 본 논문에서는 classic tracker DeepSort를 다시 살펴보고 detection, embedding 및 association 등 다양한 측면에서 업그레이드 한다(S..