

Deep High-Resolution Representation Learning for Human Pose Estimation을 읽고 정리, 요약한 글입니다.
⏹️ Abstract
본 논문에서는 신뢰할 수 있는 high-resolution representation을 학습하는 데 중점을 둔 human pose estimation 문제에 관심이 있다.
대부분의 기존 방법은 high-resolution에서 low-resolution 네트워크에 의해 생성된 low resolution에서 high-resolution을 복구한다. 하지만 본 논문에서 제안 된 네트워크는 전체 프로세스를 통해 high-resolution representation을 유지한다.
본 논문은 첫 번째 단계로 high-resolution 하위 네트워크에서 시작하여 점차 high-resolution subnetwork를 하나씩 추가하여 더 많은 단계를 형성하고 multi-resolution subnetwork를 병렬로 연결한다. high-to-low resolution representation이 계속해서 다른 parallel representation으로부터 정보를 수신하여 풍부한 high-resolution representation으로 이어지도록 반복적인 multi-scale fusion을 수행한다.
결과적으로, 예측된 keypoint heat-map은 잠재적으로 더 정확하고 공간적으로 더 정확하다는 것을 발견한다.
1️⃣ Introduction
2D human pose estimation의 목표는 인체 해부학적 keypoint 또는 part(예: 팔꿈치, 손목 등)의 위치를 파악하는 것이다.
대부분의 기존 방법은 일반적으로 직렬로 연결된 high-resolution에서 low-resolution subnetwork로 구성된 네트워크를 통해 입력을 전달한 다음 해상도를 높인다.
예를 들어, Hourglass는 대칭적인 low-resolution에서 high-resolution 프로세스를 통해 high-resolution을 복구한다. Simple-Baseline은 high-resolution representation을 생성하기 위해 몇 개의 transposed convolution layer를 채택한다.
또한 dilated convolution은 high-resolution에서 low-resolution network의 later layer(예: VGGNet 또는 ResNet)를 blow up하는 데도 사용된다.
본 논문은 전체 프로세스에서 high-resolution representation을 유지할 수 있는 새로운 아키텍처, 즉 HRNet을 제시한다.
first stage에서 high-resolution subnetwork에서 시작하여 점차 high-resolution subnetwork를 하나씩 추가하여 더 많은 stage를 형성하고 multi-resolution subnetwork를 병렬로 연결한다.
이렇게, 전체 프로세스에 걸쳐 parallel multi-resolution subnetworks에서 정보를 교환함으로써 반복적인 multi-scale fusion을 수행하고, 네트워크에 의해 출력 되는 high-resolution representation에 대한 keypoint를 estimation한다.
그림 1은 본 논문이 제시하는 새로운 아키텍쳐인 HRNet을 설명한다.
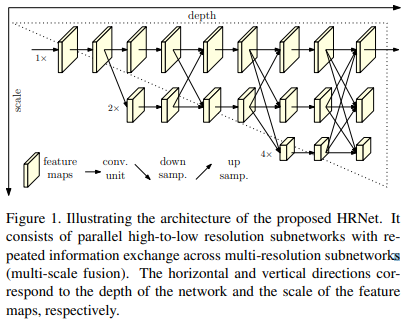
HRNet은 pose estimation에 널리 사용되는 기존 네트워크와 달리 두 가지 이점이 있다.
(i) 본 논문의 접근 방식은 대부분의 high-to-low resolution subnetwork를 병렬로 연결한다는 것이다. 따라서 low-resolution에서 hight-resolution 프로세스를 통해 resolution을 복구하는 대신 hight-resolution을 유지할 수 있으며, 예측된 heat map이 잠재적으로 공간적으로 더 정확하다.
(ii) 대부분의 기존 fusion scheme는 low-level과 highlevel representation을 집계한다. 대신, 동일한 depth와 유사한 level의 low-resolution representation의 도움을 받아 high-resolution representation을 강화하기 위해 반복적인 multiscale fusion을 수행하여 high-resolution representation이 pose estimation에서도 풍부(rich)해지도록 한다.
결과적으로, 예측된 heatmap이 잠재적으로 더 정확하다.
2️⃣ Related Work
single-person pose estimation에 대한 대부분의 전통적인 솔루션은 probabilistic graphical model 또는 pictorial structure model을 채택하는데, 이는 최근 딥러닝을 활용함으로써 개선되었다.
pose estimation의 주요 방법에는 keypoint의 position regressing 방법과 가장 높은 heatvalue를 keypoint로 하는 위치를 선택하는 keypoint heatmap estimation 방법이 있다.
keypoint heatmap estimation을 위한 대부분의 convolutional neural network은 입력과 동일한 해상도로 representation을 생성하는 본체(main body)인 classification network와 유사한 stem subnetwork로 구성되며, keypoint 위치가 추정된 후 heatmap을 추정하는 regressor가 뒤따른다.
본체(main body)는 주로 high-to-low framework와 low-to-high framework를 채택하며, multi-scale fusion 및 intermediate(deep) supervision으로 augmentation 될 수 있다.
◾ High-to-low and low-to-high
high-to-low process는 low-resolution및 high-level representation을 생성하는 것을 목표로 한다.
low-to-high process는 highresolution representation을 생성하는 것을 목표로 한다.
두 프로세스 모두 성능 향상을 위해 여러 번 반복될 수 있다.
대표적인 network design pattern은 아래와 같다.
(i) 대칭적인 high-to-low와 low-to-high processe
: Hourglass는 low-to-high process를 high-to-low process의 거울로써 설계한다.
(ii) 무거운 high-to-low와 low-to-high
: high-to-low process는 ImageNet classification network를 기반으로 하며, low-to-high process는 단순한 몇 개의 bilinear-upsampling 또는 transpose convolution layer이다.
(iii) Combination with dilated convolutions
: ResNet 또는 VGGNet의 마지막 두 stage에서 dilated convolution이 채택되어 spatial resolution loss 제거하고, 이어서 해상도를 추가로 높이기 위한 가벼운 low-to-high process가 수행되어 dilated convolution만 사용하기 위한 비싼 계산 비용을 피할 수 있다.
그림 2는 4개의 대표적인 pose estimation 네트워크를 나타낸다.

◾ Multi-scale fusion
간단한 방법은 multi-resolution 이미지를 여러 네트워크에 별도로 공급하고 output response map을 집계하는 것이다.
Hourglass와 이를 기반으로 한 확장 네트워크들은 high-to-low process의 low-level feature skip connection을 통해 low-to-high process의 동일한 resolution high-level feature로 결합한다.
pyramid network에서, globalnet은 high-to-low process의 low-to-high level feature들을 low-tohigh process로 점진적으로 결합한다. 그 후 refinenet은 convolution을 통해 처리되는 low-to-high level feature들을 결합한다.
본 논문이 제시하는 접근 방식은 deep fusion과 extension에서 영감을 받은 multi-scale fusion을 반복한다.
◾ Intermediate supervision
이미지 분류를 위해 초기에 개발된 Intermediate supervision 또는 deep supervision도 deep network 학습을 돕고 heatmap estimation 품질을 개선하기 위해 채택된다.
hourglass approach과 convolutional pose machine 접근법은 중간 heatmap을 나머지 subnetwork의 입력 또는 일부로 처리한다.
◾ Our approach
본 논문에서 제시한 네트워크는 high-to-low subnetwork를 병렬로 연결한다.
공간적으로 정밀한 heatmap estimation을 위해 전체 프로세스를 통해 high-resolution representation을 유지한다. high-to-low subnetwork에서 생성된 representation을 반복적으로 융합하여 신뢰할 수 있는 high-resolution representation을 생성한다.
별도의 low-to-high upsampling process가 필요하고 low-level 및 high-level representation을 집계해야 하는 대부분의 기존 작업과 달리 intermediate heatmap supervision을 사용하지 않는 본 논문의 접근 방식은 keypoint detection 정확도 측면에서 우수하며 계산 복잡성과 매개 변수 측면에서 효율적이다.
3️⃣ Approach
human pose estimation은 size W×H×3의 이미지 I에서 keypoint K 또는 part(예: 팔꿈치, 손목 등)의 위치를 감지하는 것을 목표로 한다.
SOTA는 이 문제를 size W’×H’, {H1, H2, . HK}의 Kth heatmap estimation으로 변환하며, 각 heatmap Hk는 keypoint의 위치를 나타낸다.
본 논문은 해상도를 감소 시키는 두 개의 stride convoultion으로 구성된 시스템으로, 입력 feature map과 동일한 해상도로 feature map을 출력하는 main body(본체), keypoint가 있는 heatmap을 추정하는 regressor로 구성된 convolution network를 사용한다.

본 논문은 main body의 설계에 초점을 맞추고 그림 1에 묘사된 High-Resolution Net(HRNet)를 소개한다.
◾ Sequential multi-resolution subnetworks
pose estimation을 위한 기존 네트워크는 high-tolow resolution subnetwork를 직렬로 연결하여 구축되는데, 여기서 stage를 형성하는 각 subnetwork는 일련의 convolution으로 구성되며 resolution을 절반으로 줄이기 위해 인접한 subnetwork에 걸쳐 down-sample layer이 있다.
Nsr을 s번째 stage의 subnetwork로 하고 r을 resolution 지수로 할 때(resolution은 첫 번째 subnetwork의 resolution의 1/2^(r-1)), S(예: 4 stage) 단계를 갖는 high-to-low network는 다음과 같이 나타낼 수 있다:

◾ Parallel multi-resolution subnetworks
본 논문은 firtst stage에서 high-resolution subnetwork부터 시작하여 점차 high-to-low resolution subnetwork를 하나씩 추가하여 새로운 stage를 형성하고 multi-resolution subnetwork를 병렬로 연결한다.
결과적으로, 이후 stage의 병렬 subnetwork에 대한 resolution은 이전 stage의 resolution과 추가로 낮은 stage의 resolution으로 구성된다.
4개의 병렬 subnetwork를 포함하는 네트워크 구조의 예는 다음과 같다:

◾ Repeated multi-scale fusion
본 논문은 각 subnetwork가 다른 병렬 subnetwork로부터 정보를 반복적으로 수신하도록 병렬 subnetwork에 exchange unit을 도입한다.
다음은 정보 교환 방식을 보여주는 예시이다.

세 번째 단계를 여러 개(예를 들어 3개)의 exchange block으로 나누었고, 각 블록은 다음과 같이 병렬 단위에 걸쳐 exchange unit을 갖는 3개의 병렬 convolution unit으로 구성되어 있는데, 여기서 C는 b번째 블록의 r번째 resolution에서 convolution unit을 나타내고 Ebs는 해당 exchange unit을 나타낸다.

그림 3에서 exchange unit을 나타낸다.
편의를 위해 subscript s와 superscript b를 삭제하고 입력은 s response map으로 하여 다음과 같은 공식을 제시한다: {X1, X2, ., Xs}.
출력은 resolution과 width가 입력과 동일한 s response map {Y1, Y2, ., Ys}이다. 각 출력은 input map의 집합 Yk이다.
여러 stage에 걸친 exchange unit에는 추가 output map Ys+1: Ys+1 = a(Ys, s + 1)가 있다.
함수 a(Xi, k)는 resolution i에서 resolution k로 Xi를 upsampling 또는 downsampling 하는 것으로 구성된다. downsampling을 위해 stride 3×3 convolution을 채택한다.
◾ Heatmap estimation
본 논문은 마지막 exchange unit에 의해 출력 된 high-resolution representation에서 단순히 heatmap을 회귀 시킨다. 평균 제곱 오차로 정의되는 손실 함수는 예측 heatmap과 GT heatmap을 비교하는 데 적용된다.
GT heatmap은 각 keypoint의 GT 위치를 중심으로 1픽셀의 표준 편차를 갖는 2D 가우스를 적용하여 생성된다.
◾ Network instantiation
ResNet의 설계 규칙에 따라 각 stage에 대한 depth와 각 resolution에 대한 채널 수를 분배하여 keypoint heatmap estimation을 위한 네트워크를 인스턴스화 한다.
main body, 즉 HRNet은 4개의 병렬 subnetwork가 있는 4개의 stage를 포함하며, resolution은 점차 절반으로 감소하고 그에 따라 채널 수는 2배로 증가한다.
첫 번째 stage는 ResNet-50과 동일한 4개의 residual unit을 포함하며, 각 unit은 width 64의 bottleneck에 의해 형성되며, 이어서 feature map widht를 C로 줄이는 3×3 convolution이 뒤따른다.
2단계, 3단계, 4단계는 각각 1, 4, 3개의 exchange block을 포함한다. 하나의 exchange block은 각 stage가 각 resolution에 두 개의 3×3 convolution을 포함하는 4개의 residual unit과 resolution에 걸친 exchange unit을 포함한다.
요약하면 총 8개의 exchange unit이 있으며, 이는 8개의 multi-scale fusion이 수행된다는 것을 의미한다.
실험에서, small-network인 HRNet-W32와 large-network인 HRNet-W48을 연구했다.
여기서 32와 48은 각각 마지막 3단계의 high-resolution subnetwork의 폭(C)을 나타낸다.
다른 세 개의 병렬 subnetwork의 width는 HRNet-W32의 경우 64, 128, 256, HRNet-W48의 경우 96, 192, 384이다.
4️⃣ Experiments - 생략
5️⃣ Conclusion and Future Works
본 논문에서는 human pose estimation을 위한 high-resolution network를 제시하여 정확하고 공간적으로 정확한 keypoint heatmap 산출한다.
본 논문에서 제시한 접근법은 high-resolution을 복구할 필요 없이 전체 프로세스를 통해 high-resolution을 유지하고 multi-resolution representation을 반복적으로 융합하여 신뢰할 수 있는 high-resolution representation을 렌더링 한다.
향후 연구에는 instance segmentation, object detection, face 정렬, 이미지 captioning과 같은 다른 밀도 높은 예측 작업에 대한 응용 뿐만 아니라 multi-resolution representation을 덜 가벼운 방식으로 집계하는데 대한 조사가 포함된다.
논문을 읽은 후 제가 알고 있는 선에서 최대한 정리하고 요약한 글입니다. 때문에 해당 포스팅에 대한 의견 제시 및 오타 정정은 언제나 환영입니다!
늦더라도 댓글 남겨주시면 확인하겠습니다!