

Lite Pose: Efficient Architecture Design for 2D Human Pose Estimation, Yihan Wang et al., 2022 을 읽고 정리, 요약한 글입니다.
▪️ 본 논문의 기여 내용 요약
- gradual shrinking 실험을 설계하여 high-resolution branch가 저연산 영역의 모델에 중복된다는 것을 밝힌다.
- bottom-up pose estimation을 위한 효율적인 아키텍처인 LitePose를 제안한다. 또한 fusion deconv head와 large kernel conv를 포함해 LitePose의 capicity를 향상 시키는 두 가지 기술을 소개한다.
- Microsoft COCO와 CrowdPose라는 두 가지 benchmark dataset에 대한 광범위한 실험은 우리 방법의 효과를 입증한다. LitePose는 최첨단 HRNet 기반 모델에 비해 최대 2.8배의 MAC 감소와 최대 5.0배의 지연 시간 감소를 달성한다.
⏹️ Abstract
리소스가 제한된 edge 장치에 HRNet 기반 SOTA pose estimation 모델을 배치하는 것은 어렵다(프레임 당 150 GMACs 이상). 때문에 본 논문에서는 실시간 multi pose estimation을 위한 효율적인 아키텍처 설계를 연구한다.
본 논문은 HRNet의 high-resolution branche가 gradual shrinking 실험을 통해 저연산 영역의 모델에 중복된다는 것을 밝혔다. 이를 제거하면 효율성과 성능이 모두 향상된다는 발견에서 영감을 받아 pose estimation을 위한 효율적인 single-branch architecture인 LitePose를 설계하고 Fusion Deconv Head 및 Large Kernel Convs를 포함한 LitePose의 capacity를 향상 시키기 위한 두 가지 간단한 접근 방식을 소개한다.
Fusion Deconv Head는 high-resolution branche의 중복성을 제거하여 낮은 오버헤드로 scale-aware feature fusion을 가능하게 한다. Large Kernel Convs significantly는 낮은 계산 비용을 유지하면서 모델의 용량과 receptive field를 크게 향상 시킨다.
1️⃣ Introduction
일반적인 human pose estimation 모델은 top-down과 bottom-up의 두 가지 패러다임으로 분류할 수 있다.
top-down 패러다임은 먼저 person detector를 통해 사람을 detection 한 다음 detection 된 각 개인에 대해 단일 human pose estimation을 수행한다.
대조적으로, bottom-up 패러다임은 먼저 정체성이 없는 핵심 포인트를 예측한 다음 사람으로 그룹화 한다. bottom-up 패러다임은 추가 person detector를 포함하지 않으며 이미지의 각 사람에 대한 pose estimation 모델을 반복적으로 실행할 필요가 없으므로 edge에서 실시간 다중 human pose estimation에 더 적합하다.
그러나 기존의 bottom-up pose estimation 모델은 주로 높은 계산 영역에 초점을 맞춘다. 예를 들어, HigherHRNet은 150GMACs 이상으로 CrowdPose dataset에서 최고의 성능을 달성하는데, 이는 edge 장치에서 적용할 수 없다.
본 논문에서는 bottom-up human pose estimation을 위한 효율적인 아키텍처 설계를 연구한다.
저연산 영역의 모델에서 high-resolution representation을 유지하는 것이 bottom-up pose estimation의 우수한 성능을 달성하는 데 중요한 역할을 하는지는 불분명하다. 따라서, 본 논문은 대표적인 multi-branch architecture인 HigherHRNet과 single-branch architecture 사이에 gradual shrinking를 통해 "bridge"를 구축한다(그림 2).

놀랍게도 저연산 영역의 모델에 대한 high-resolution branch의 depth를 줄이면 성능이 향상된다는 것을 발견했다(그림 3).

이 발견에서 영감을 받아 효율적인 bottom-up pose estimation을 위해 single-branch architecture인 LitePose를 설계했다.
LitePose에서, single-branch 설계에서 스케일 변동 문제를 효율적으로 처리하기 위해 두 가지 중요한 개선 사항( fusion deconv head와 large kernel conv)이 있는 수정된 MobileNetV2 백본을 사용한다. fusion deconv head는 high-resolution branch의 redundant refinement를 제거해 single-branch 방식으로 scale-aware multi-resolution fusion을 가능하게 한다(그림 6).

한편, image clasiification과는 달리, large kernel conv이 bottom-up pose estimation에서 훨씬 더 눈에 띄는 개선을 제공한다는 것을 발견했다(그림 7).

마지막으로 Neural Architecture Search(NAS)를 적용하여 모델 아키텍처를 최적화하고 적절한 입력 해상도를 선택한다.
2️⃣ Related Work
◾ 2D Human Pose Estimation
이러한 접근법 중에서, HRNet은 bottom-up pose estimation을 위한 스케일 변동 문제를 해결하는 데 효과적인 것으로 입증된 multi-resolution fusion을 허용하기 위해 multi-branch 아키텍처를 설계했다.
그러나 이러한 모든 접근 방식은 edge 장치에 배포하기에는 어려움이 있어 효율성을 위한 bottom-up 프레임워크에 초점을 맞춰 그룹화를 위한 associative embedding을 사용한다.
2D human pose estimation에는 top-down 프레임워크와 bottom-up 프레임워크가 있는데, 일반적인 bottom-up 방법은 keypoint heatmap을 예측한 다음 detection 된 keypoint를 사람으로 그룹화 하는 두 단계로 구성된다.
◾ Model Acceleration
한편, 일부 다른 방법들은 네트워크를 양자화(quantizing)하는 데 초점을 맞춘다. 또한 모델 압축 및 가속을 자동화하기 위해 여러 AutoML 방법이 제안 되었다.
최근에 top-down pose estimation을 위해 bottom-up 패러다임에 초점을 맞춘 LiteHRNet이 설계 되었으며 효율적인 bottom-up pose estimation을 위한 EfficientHRNet도 제안하였으며, EfficientNet의 compound scaling 아이디어를 HigherHRNet에 적용하여 1.5배의 MACs 감소를 달성한다.
효율적인 모델을 직접 설계하는 것 외에도, 모델 가속을 위한 또 다른 접근법은 기존의 대형 모델을 압축하는 것이다. 일부 방법은 connection 및 convolution filter 내부의 중복성을 제거하는 것을 목표로 한다.
◾ Neural Architecture Search
검색 프로세스를 보다 효율적으로 만들기 위해 서로 다른 하위 네트워크가 동일한 가중치 집합을 공유하는 One-shot NAS 방법을 제안했으며 채널 내부의 중복성을 자동으로 제거하고 적절한 input size를 선택하는 once-for-all 접근 방식을 적용한다.
처음부터 scratch로 학습된 수동 설계 모델과 비교하면, 검색된 모델은 최대 +3.6AP까지 개선되는 눈에 띄는 성과를 달성한다.
Neural Architecture Search(NAS)은 대규모 image classification task에서 큰 성공을 거두었다.
3️⃣ Rethinking the Efficient Design Space
Multi-branch network는 bottom-up pose estimation task에서 큰 성공을 거두었는데, 대표적으로 HigherHRNet은 multi-branch architecture를 사용하여 multi-resolution feature를 융합하여 스케일 변동 문제를 크게 완화한다. 이를 통해 multi-branch 아키텍처는 single brach 아키텍처를 능가하는 SOTA를 달성했다. 그러나 이러한 방법의 대부분에는 150이상의 GMACs로 높은 계산으로 수행된다.
해당 섹션은 HRNet 기반 multi-branch 아키텍처와 이 아키텍처가 스케일 변동 문제를 처리하는 방법과 계산적으로 제한된 경우에서 gradual shrinking으로 high-resolution branch의 중복성에 대해 설명한다.
본 논문은 high-resolution branch의 중복 정제를 제거하여 스케일 변동 문제를 효율적인 방식으로 처리하는 fusion deconv head를 제안하고, 경험적으로 큰 커널이 image classification task에 비해 pose estimation 작업에서 훨씬 더 눈에 띄는 개선을 제공한다는 것을 발견했다.
◾Scale-Aware Multi-branch Architectures
▪️ Scale-Awareness
multi-branch design는 bottom-up pose estimation에서 스케일 변동 문제를 완화하는 것을 목표로 한다.

이미지에서 모든 사람의 관절 좌표를 예측해야 하기 때문에, 그림 5(b)에 나온 것처럼 single-branch 구조가 일반적으로 작은 사람을 인식하고 근접한 관절을 최종 low-resolution feature와 구별하기 어렵다.
그러나 multi-branch 아키텍처에 의해 도입된 high-resolution feature 더 자세한 정보를 판단(reserve)할 수 있으므로 neural network 작은 사람을 더 잘 포착하고 가까운 관절을 구별하는 데 도움이 된다.
▪️ Mechanism
그림 2와 같이, HRNet 기반 multi-branch 아키텍처의 주요 부분은 4단계로 구성된다.
n단계(여기서는 스템을 1단계로 간주)에서 각각 다른 해상도를 가진 n개의 다른 input feature map을 처리하는 branch가 있다. input feature를 처리할 때 각 branch는 자체 input feature를 각각 세분화한 다음 branch 간에 정보를 교환하여 multi-scale 정보를 얻는다.
◾ Redundancy in High-Resolution Branches
multi-branch 아키텍처의 high-resolution branch에서 중복성을 드러내기 위해 gradual shrinking라는 방법을 제안한다.

그림 2와 그림 3에서 보는 바와 같이, high-resolution branch의 depth를 점차 축소함으로써, multi-branch 네트워크는 점점 더 single-branch 네트워크처럼 동작한다.
그러나 성능이 저하되는 것은 아니며, 심지어 향상되기도 한다.
▪️ Gradual Shrinking
HRNet 기반 multi-branch 아키텍처 내부의 중복성을 드러내기 위해, 본 논문은 각 단계의 branch에 대한 gradual shrinking 실험을 설계한다. An = [a1, . . . . , an]은 융합 전 n단계에서 각 branch에 대한 feature를 다듬는 데 사용되는 블록의 수를 나타낸다(ai는 branch i의 블록 수를 의미). 여기서 브랜치 i는 브랜치 i + 1보다 해상도가 높은 feature map을 처리한다.
그런 다음 전체 multi-branch 아키텍처의 구성을 A = {A1, A2, A3, A4}로 정의할 수 있다. 본 논문은 만약 ∀j ∈ {1, ., i}, a'j ≤ ai 일때, A'i = [a'1, ., a'i]는 Ai = [a1, . . ., ai]로부터 축소되는데, 편의상 이를 A'i ≤ Ai로 표기한다. ∀i ∈ {1, 2, 3, 4}, A'i ≤ Ai이면, configuration A'는 A로부터 축소된다고 한다.
점진적 축소 실험에서 네 가지 아키텍처 구성. 우리는 비교를 위한 기준으로 Scaled-HigherHRNet2를 사용한다. 제거된 블록은 투명하게 표시됩니다. 네트워크는 기준선에서 축소 3으로 단일 분기 아키텍처에 점점 더 가까워지고 있다. 서로 다른 아키텍처 구성이 유사한 MAC을 갖도록 하기 위해 Shrink2 및 Shrink3의 기본 채널을 16개에서 18개로 늘렸습니다.
그림 2와 그림 3에서 볼 수 있듯이, 본 논문 high-resolution branch의 depth를 점차 축소하고 놀랍게도 이러한 축소 작업이 성능 향상에도 도움이 된다는 것을 발견했다.
한편, gradual shrinking 프로세스는 전체 네트워크를 single-branch 네트워크와 점점 더 유사하게 만들어 single-branch 아키텍처가 bottom-up pose estimation 작업의 효율적인 아키텍처 설계에 더 적합하다는 강력한 증거를 제공한다.

본 논문은 gradual shrinking 프로세스를 명확하게 만들기 위해 사용하는 위와 같은 4가지 configuration을 자세히 나열한다.
◾ Fusion Deconv Head: Remove the Redundancy
single-branch 아키텍처의 장점(예: high efficiency)을 유지하면서 이 feature를 본 논문에서 제시하는 아키텍쳐에 결합하기 위해, 본 논문은 fusion deconvolution layer를 최종 prediction head로 제안한다.


구체적으로 그림 4와 6(b)에 나온 것처럼 deconvolution 및 final prediction layer에 대해 이전 단계에서 생성된 low-level high-resolution feature를 직접 활용한다.
한편, LitePose는 single-branch 아키텍처를 backbone으로 사용하여 latency가 짧은 특성의 이점을 활용한다.
또, low-level high-resolution feature 직접 사용하면 multi-branch HR fusion 모듈의 중복 정제를 피할 수 있다.
따라서 LitePose는 single-branch 설계와 multi-branch 설계의 장점을 효율적인 방식으로 상속한다. 그림 6(a)와 그림 5에서 본 논문은 fusion deconvolution head의 strength를 보여주며, 무시할 수 있는 정도의 약간의 계산 비용 증가로 상당한 성능 향상(+7.6AP)을 얻을 수 있었다.
◾ Mobile Backbone with Large Kernel Convs
그림 4와 같이, 본 논문은 LitePose의 backbone으로 수정된 MobileNetV2 아키텍처를 사용한다. 본 논문 final down-sampling stage를 제거하여 원래 MobileNetV2 backbone에 대해 사소한 수정을 한다.
down-sampling layer가 너무 많으면 필수적인 정보 손실이 발생하여 pose estimation 작업의 high-resolution output에 좋지 않다. 스케일 변동 문제를 더욱 완화하기 위해 효율적인 아키텍처 설계에 large kernel을 도입한다. 기존의 image classification task과 달리, 이 수정은 제안 된 MobileNetV2 기반 backbone에서 훨씬 더 중요한 역할을 한다.

그림 7에서는 image classification과 pose estimation 작업 모두에서 커널 크기가 3, 5, 7(pose estimation에 한해 9)인 모델 간의 성능 비교를 보여준다.
계산 비용 증가(약 +25%)로 인한 pose estimation 작업의 성능 향상(+13.0AP)은 image classification 작업(+1.5% Acc)보다 훨씬 더 중요하다.
그림 5의 시각화 결과도 본 논문의 주장을 입증한다.
그러나 규칙은 "크면 클수록 좋다"는 것이 아니다.
커널이 너무 크면 많은 쓸모없는 매개 변수와 무시할 수 없는 노이즈가 발생하며, 이는 k = 9 경우에 대해 그림 7에서 입증된 학습을 더 어렵게 하고 성능 저하를 초래한다.
search space에 kernel size를 통합하면 섹션 4에서 언급한 NAS의 성능이 크게 저하될 수 있으므로, 우리는 아키텍처에서 kernel size를 7×7로 고정한다.
◾ Single Branch, High Efficiency
그림 3에서 Scaled-HigherHRNet-W16과 LitePose-L 사이의 정량적 비교 결과를 보여주는데, 스케일이 큰 HRNet-W16과 비교하여 LitePose-L은 훨씬 더 나은 성능을 달성할 뿐만 아니라(+11.6AP), 더 큰 MACs에서도 Qualcomm Snapdragon 855에서 유사한 latency 얻는다.
이 모든 결과는 single-branch LitePose의 높은 효율성을 보여준다.
4️⃣ Neural Architecture Search
bottom-up pose estimation 작업에 대한 기존 작업은 일반적으로 모델의 모든 layer에 걸 hand-crafted(그리고 대부분 균일) channel width와 고정된 큰 해상도(예: 512 × 512)를 사용한다.
이 섹션에서는 채널의 중복성을 자동으로 제거하고 최적의 input resolution를 선택하기 위해 once-for-all을 적용한다.
◾ Optimization Goal
원래 LitePose 아키텍처가 각 layer에 {ck}K~k=1개의 채널을 포함한다고 가정할 때, (여기서 K는 네트워크의 계층 수를 나타냄) optimization goal(최적화 목표)은 채널 width가 {c'k}K~k=1인 input resolution가 r' < r인 하위 네트워크를 찾는 것이며, 여기서 c'k ≤ ck는 최고의 Average Precision(AP)를 달성하면서 효율성 제약을 충족할 수 있다.
◾ One-shot Supernet Training
supernet이 그룹화를 위한 임베딩과 관련하여 더 잘 학습할 수 있도록 돕기 위해, 본 논문은 pre-trained 된 가중치로 supernet을 초기화한다.
먼저 가중치 공유를 통해 다양한 채널 번호 구성을 지원하는 LitePose supernet을 학습 시킨다. 각 훈련 반복에 대해 채널 구성을 균일하게 샘플링하고 이를 사용하여 supernet을 훈련 시킨다. 이러한 방식으로 각 구성은 동일하게 훈련되며 독립적으로 작동할 수 있다.
◾ Search & Fine-tune
본 논문은 진화 알고리듬을 사용하여 특정 효율 제약 조건(예: MAC)이 주어진 최적의 구성을 찾는다.
supernet은 철저히 가중치 공유로 학습 되기 때문에, 특정 하위 네트워크의 가중치를 직접 추출하고 추가 fine-tuning없이 하위 네트워크를 평가할 수 있다. 이는 서브 네트워크의 최종 성능에 근접한다.
5️⃣ Experiments - 간단 정리
◾ Large Kernels
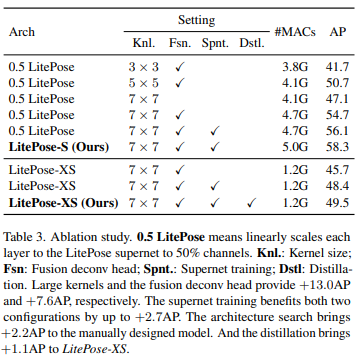
표 3에서 볼 수 있듯이, 약간의 계산 증가만으로 7×7 커널은 스케일 변화 문제에 대처하는 능력을 향상 시켜 최상의 성능을 제공한다.
◾ Fusion Deconv Head
표 3과 그림 6에서 성능 향상을 정량적으로 보여준다: 효율적인 fusion deconv head는 계산이 약간 증가한 CrowdPose 데이터 세트에 대해 성능을 +7.6AP 향상 시킨다.
스케일 변동 문제를 처리하는 또 다른 방법은 large resolution feature의 도입이 작은 사람들을 더 잘 포착하는 데 도움이 될 수 있기 때문에 multi-resolution fusion이다.

◾ Neural Architecture Search
표 3과 같이 supernet 학습은 0.5LitePose 및 LitePose-XS에서 +1.4AP 및 +2.7AP를 달성했다. 아키텍처 검색도 0.5LitePose에서 +2.2AP를 제공했으며, LitePose-XS의 경우, fine-tuning에서 heatmap loss을 위해 LitePose-S를 teacher로 사용하고 +1.1AP을 얻는다.


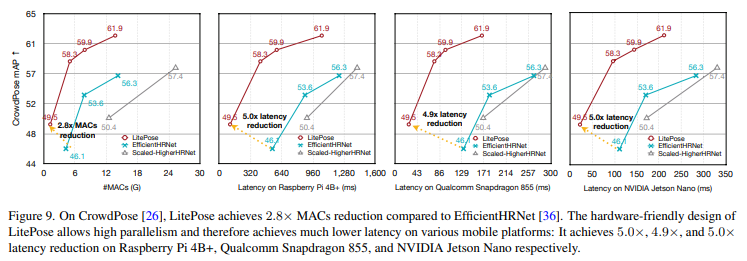
표 1과 그림 9에서 보는 바와 같이, 본 논문에서 제안하는 아키텍처는 HRNet 기반 방법에 비해 모바일 플랫폼에서 2.8배의 MAC 감소와 최대 5.0배의 latency 감소를 달성한다.
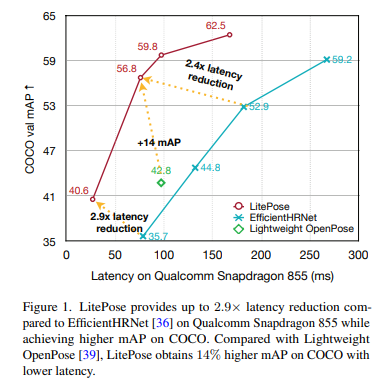

표 2와 그림 1에서 볼 수 있듯이, 본 논문의 아키텍처는 훨씬 더 높은 성능으로 최대 2.4배의 성능을 달성한다.
게다가, Lightweight Openpose와 비교했을 때, 본 논문에서 제시한 방법은 모바일 플랫폼에서 더 적은 latency로 훨씬 더 나은 성능을 발휘한다(+14.0AP).
6️⃣ conclusion
본 논문에서는 edge device에서 multi-person pose estimation을 위한 효율적인 아키텍처 설계를 연구하여 multi-branch 및 single branch 아키텍처를 연결하기 위해 gradual shrinking 실험을 설계했다. 이 연구는 high-resolution branch가 low-computation 영역의 모델에 중복된다는 것을 보여준다.
이에 영감을 받아 multi-branch 및 single branch 아키텍처의 장점을 모두 상속하는 pose estimation을 위한 효율적인 아키텍처인 LitePose를 제안한다. 또한 human pose estimation 작업에서 큰 커널이 작은 커널보다 훨씬 더 잘 작동한다는 흥미로운 현상을 관찰한다. 이러한 실험은 LitePose의 효과와 견고성을 입증하여 edge 애플리케이션에 대한 실시간 human pose estimation의 길을 열었다.
논문을 읽은 후 제가 알고 있는 선에서 최대한 정리하고 요약한 글입니다. 때문에 해당 포스팅에 대한 의견 제시 및 오타 정정은 언제나 환영입니다!
늦더라도 댓글 남겨주시면 확인하겠습니다!