

Object Detection in Aerial Images:A Large-Scale Benchmark and Challenges, Jian Ding et al., Feb 24, 2021을 읽고 요약한 글입니다.
Abstract
위성 이미지에 대한 대 용량 벤치마크의 부족이 ODAI(object detection in aerial images, 위성 이미지에서의 객체 검출)의 object detection 발전에 큰 장애물이 된다. 해당 논문에서는 대용량 데이터셋(DOTA)과 ODAI에 대한 포괄적인 기준을 제시한다.
1. Introduntion
현재 Earth Vision(지구 관측 및 원격 감지라고도 함.) 기술은 최애 0.5m 해상도의 위성 이미지로 지구를 관찰할 수 있을 만큼 발전했다. 방대한 양의 이미지를 해석하기 위해선 수학적 도구와 수치 알고리즘의 개발이 필요하지만 object detection 또한 중요하다. object detection이란 지상에 관심 있는 객체(ex.차량, 선박)의 위치를 파악 후 그 객체의 범주를 예측하는 것을 의미한다.

ODAI의 object detection은 도시 관리, 농업, 긴급 구조 등과 같은 실제 응용 분야에서 필수적인 단계이다. 많은 연구로 기술의 발전이 이루어지고 있지만 위 Figure1과 같이 임의의 방향, 스케일 변화, 극도로 불균일한 객체의 밀도 및 큰 가로, 세로의 비율(aspect ratios, ARs)과 같은 문제를 해결해야만 한다.
이런 문제들 중 overhead view로 인해 발생하는 객체의 임의의 방향은 실제 이미지와 위성 이미지 간의 가장 큰 차이이며 이는 2가지 방법으로 object detection 작업을 복잡하게 만든다.
첫째, rotation-invariant한 features의 표현은 임의의 방향의 물체를 탐지할 때 선호되긴 하지만 현재의 대부분 심층 신경망 모델의 능력을 벗어나는 경우가 많다. 이를 위해 rotation-invariant CNN을 사용해 봤지만 문제는 해결되지 않았다. 둘째, 기존의 object detection에 사용되는 HBB(the horizontal bounding box)sms Figure1에서의 선박 및 대형 차량과 같은 oriented objects의 위치를 제대로 파악할 수 없다. 오히려 OBB(Oriented Bounding Box)가 위성 사진에 더 적합하다. OBB를 사용한 object detection은 밀집된 instance를 구별하고 rotation-invariant 기능을 추출할 수 있다. OBB는 oriented object detection이라는 새로운 object detection task를 도입했다. 대용량의 주석이 달린 위성 이미지의 데이터셋 부족으로 인해 ImageNet 및 MS COCO와 같은 이미지 데이터셋에서 사전 훈련된 딥 러닝 기반의 oriented object detection을 위성 이미지에 적용시키는 방법 중 하나이다.
ODAI의 또 다른 문제는 자연 이미지에서 학습한 기존 object detection의 모듈 설계와 하이퍼파라미터 설정이 영역 차이로 인해 위성 이미지에 적합하지 않다는 것이다. 때문에 알고리즘 개발 관점에서 위성 이미지에 대한 모델의 포괄적인 기준선과 충분한 ablative 분석이 필요하다. 그러나 하드웨어, 소프트웨어 플랫폼, 세부 설정 등이 다양해서 서로 다른 알고리즘을 비교하는 것은 어려우며 이러한 요인들은 속도와 정확도 모두에 영향을 미친다. 따라서 기준선을 구축할 땐 알고리즘을 통일된 코드 라이브러리로 구현해야 하며 하드웨어와 소프트웨어 플랫폼을 동일하게 유지해야만 한다.
그럼에도 불구하고 MMDetection 및 Detectron과 같은 현재 object detection 라이브러리는 oriented object detection을 지원하지 않는다.
이러한 문제를 해결하기 위해 해당 논문에서는 DOTA의 예비 버전인 DOTA-v1.0을 DOTA-v2.0으로 확장한다. DOTA-v2.0은 18개의 공통 카테고리에서 OBB로 주석을 단 약 180만개의 object instance들을 포함하고 있다. 해당 논문은 알고리즘 개발과 DOTA와의 비교를 용이하게 하기 위해 위성 이미지에서 oriented object detection을 지원하는 HBB 및 OBB를 모두 사용하여 코드 라이브러리를 구축하고 총 10개의 알고리즘과 각각 다르게 설계된 70개 이상의 모델을 평가한다. 향후 연구를 위하여 속도 및 정확도를 분석하여 위성 이미지에서 모듈 설계 및 매개 변수 설정을 탐색한다.
이러한 실험은 자연 이미지와 위성 이미지 사이의 object detection 설계의 큰 차이를 검증하고 보편적인 object detection 알고리즘을 위한 재료를 제공한다.
2. Related Work
이 섹션에서는 자연 이미지와 위성 이미지의 object detection 데이터 셋을 간략히 검토한다.
PASCAL VOC(Visual Object Class)은 2005년부터 2012년까지 object detection에 대해 도전을 해 왔다. PASCAL VOC Challenge 2012 데이터 세트에는 11개, 이미지 530개, 클래스 20개 및 27개, 주석이 달린 경계 상자가 포함되어 있다.
후에 200개의 클래스와 약 500,000개의 주석이 달린 바운딩 박스를 포함하는 ImageNet 데이터셋이 개발되었다.
다음으로는 그런 다음 총 328K개의 이미지, 91개 카테고리 및 2.5백만 개의 라벨이 지정된 세그먼트 객체를 포함하는 MS COCO가 발표되었다. MS COCO는 평균적으로 이미지당 더 많은 instance와 카테고리를 가지고 있으며 PASCAL VOC 및 ImageNet보다 더 많은 컨텍스트 정보를 포함한다.
800개의 이미지, 10개의 클래스 및 3651개의 인스턴스만 포함하는 NWPU와 같은 일부 공용 데이터셋은 여러 카테고리를 가지고 있지만 표본 수는 제한적이기 때문에 모델을 학습하는데 있어 효율적이지 못하다.
위성 이미지 object detection을 위한 좋은 데이터셋은 data-driven을 용이하게 하기 위한 상당한 주석이 달린 데이터여야하며 많은 상황별 정보를 포함하는 큰 이미지여야 한다. 또, 물체의 정확한 위치를 설명하는 OBB 주석이 있어야 하며 미지 소스의 균형이 맞아야 한다.
위성 이미지의 객체는 조감도에 의해 임의로 방향이 잡히는 경우가 많으며 스케일 변화가 자연 이미지의 객체보다 크다. 이런 회전에 대한 문제를 해결하기 위해 R-CNN에 rotation-invariant 레이어를 연결한다. ORN(The oriented response network)은 능동 회전 필터(ARF, active rotating filters)를 도입하여 RRD(the rotation-sensitive regression detector)에 채택된 데이터를 사용하지 않고 rotation-invariant 특성을 생성한다. 이러한 방법들은 OBB 주석을 완전히 활용하지는 않는다.
OBB 주석을 사용할 수 있을 때. rotation R-CNN (RRCNN)은 rotation region-of-interest(RRoI) pooling을 사용하여 rotation-invariant 영역의 특징을 추출한다. 하지만 RRCNN은 수작업으로 제안을 생성한다.
RoI Transformer는 OBB의 supervision을 이용하여 RoI 방식의 공간 변환을 학습하고자 한다. 후에 S2A-Net은 1단계 검출기에서 공간적으로 변하지 않는 특징을 검출한다. 스케일 변화 문제를 해결하기 위해 feature 피라미드와 이미지 피라미드는 위성 이미지에서 스케일 불변 특징을 추출하는데 널리 사용된다.

위의 Figure3과 같이 HBB는 모여있는 instance들에 대해 정확하게 구별할 수 없다. 기존의 HBB 기반인 NMS(non maxinum suppression)은 이런 경우에서는 실패하게 된다.
이러한 문제를 해결하기 위해 정밀한 detection을 요구하는 rotated NMS(R-NMS)를 사용하는 방법들은 텍스트 및 얼굴 검출과 유사하게 정밀한 ODAI도 oriented object detection 작업으로 모델링할 수 있다. 이를 회귀 문제로 간주하고 앵커에 상대적인 OBB 지상 실측값의 오프셋을 회귀시킨다. 예를 들면, 사각형의 구석점에는 네 개의 순열이 있다. faster R-CNN OBB는 정의된 규칙을 사용하여 OBB의 점 순서를 결정함으로써 이를 해결한다. 모호성을 제거하기 위해 글라이딩 오프셋과 경사도를 추가로 사용하기도 한다. The circular smooth label(CSL)은 문제를 방지하기 위해 각도의 회귀를 분류 문제로 변환한다. Mask OBB와 CenterMap은 모호성을 피하기 위해 픽셀 수준의 분류 문제로 물체 감지를 고려한다. Mask 기반 방법은 더 쉽게 수렴되지만 회귀 기반 방법보다 부동 소수점 매초 연산(FLOPS, floating point operations per second)이 더 많다.
위성 이미지는 사이즈가 매우 크다. 현재 GPU 메모리 용량이 부작하여 대용량 이미지를 처리할 수 없으므로 큰 이미지를 작은 패치로 분할해야 한다. 이러한 패치에 대한 결과를 얻은 후 결과는 다시 큰 이미지로 통합된다. 큰 이미지에 대해 inference를 가속화하기 위해 먼저 큰 이미지에 instance를 포함할 가능성이 있는 영역을 찾은 후 해당 영역의 object를 detection한다.
Tensorflow Object Detection API, Detectron, MaskRcnn-Benchmark, Detectron2, MMDetection and SimpleDet은 object detection 코드 라이브러리로 object detection 알고리즘의 비교를 용이하게 하기 위해 개발되었다. 이러한 코드 라이브러리는 horizontal object detection에 초점이 맞춰져있지만 Detectron2는 제한적으로 oriented object detection을 지원한다.
3. Construnction Of DOTA
해당 연구진들은 해상도와 다양한 센터는 데이터셋 편향을 생성하는 요인이기 때문에 구글 어스, 위성 및 항공 이미지를 포함아여 여러 해상도의 다양한 센서와 플랫폼에서 이미지를 수집했다. DOTA의 이미지를 얻기 위해 전 세계의 RoI의 좌표를 수집했다. 총 18개의 범주를 선택했으며 종류에는 비행기, 배, 야구 베이스, 테니스 코트, 수영장, 지상 트랙 필드, 항구, 브리지, 대형 자동차, 소형 자동차, 헬리콥터, 원형 교차로, 축구장, 농구장, 공항, 헬기장 등이 있다.
computer vision에서 지역 설명, 객체, 속성 및 관계와 같은 시각적인 개념은 바운딩 박스로 표현된다. 바운딩 박스의 일반적인 표현은 (xc, yc, h)이며, 여기서 (xc, yc)는 중심 위치이고 w, h는 바운딩 박스의 폭과 높이이다. 이러한 유형의 경계 상자를 HBB라고 부르며 HBB는 대부분의 경우 물체를 잘 묘사할 수 있다.
하지만 Figure3에서 보면 HBB는 모여있는 oriented object를 구별할 수 없다. 이런 경우 기존 NMS 알고리즘은 실패하게 된다.
이런 문제로 OBB로 물체를 나타낸다. OBB는 $$ (xi, yi) | i = 1,2,3,4 $$로 나타낸다. 여기서 (xi, yi)는 OBB의 꼭짓접 위치를 나타내며 꼭지점은 시계 방향으로 배열되어 있다.
OBB에 주석을 다는 간단한 방법을 HBB를 그린 다음 각도를 조정하는 것이다. HBB에 대한 레퍼런스가 없기 때문에 임의의 oriented object를 잘 맞추기 위해 중심, 높이, 너비 및 각도에 대한 조정이 필요하다.
해당 연구진들은 주석자들이 OBB 네 모서리를 클릭할 수 있도록 했다. 대부분 번주에서 OBB의 모서리는 물체의 위 또는 가까이 놓여 있지만 OBB와 모양이 매우 다를 경우에는 4가지 핵심 포인트에 주석을 달았다. 예를 들면 윙팁 및 꼬리를 나타내는 4개의 핵심 점으로 평면에 주식을 달고 4개의 핵심 포인ㅇ트를 OBB로 전송하는 것이다. 점의 순서를 변경하여 동일한 객에체 대해 4가지의 다른 표현을 얻을 수 있는데 'HEAE'를 암시하는 첫번재 점을 신중하게 선택해야 한다. 시각적 단서가 없는 경우에는 왼쪽 상단 포인트를 출발점으로 선택하며 이에 대해서는 아래 Figure4에 나와있다.

4. Properties Of DOTA
측정된 픽셀 중심 사이의 거리를 나타내는 접지 샘플 거리(GSD)에는 잠재적인 용도가 있다. 동일한 범주의 객체 크기가 일반적으로 작은 범위로 제한되어 있기 때문에 라벨이 잘못 부착되거나 분류가 잘못 된 특이치를 필터링하는데 사용할 수 있는 객체의 실체 크기를 계산할 수 있다. 또한 객체 크기 및 GSD의 우선 순위를 기반으로 스케일 정규화를 할 수 있다.
overhead view 이미지의 객체는 중력의 제한 없이 방향의 다양성이 높다. 객체는 $$ [-pi, pi] $$ 에서 임의의 각도의 확률이 같다. 대부분의 객체의 각도는 중력 때문에 좁은 범위 내에 있다는 점에 유의해야 한다. DOTA의 고유한 각도 분포는 rotation-invariant 특징 추출 및 oriented object detection 연구에 좋은 데이터셋이 된다.
HBB 높이를 사용하여 인스턴스의 픽셀 크기를 측정하는데 HBB 높이에 따라 세 개의 분할로 데이터셋을 나눈다. 크기가 작으면 10~50 사이, 중간은 50~300 사이, 300 이상으로 나누며 MS COCO와 DOTA-v1.0은 소형 인스턴스와 중형 인스턴스 간의 균형이 잘 잡혀 있다. DOTA-v2.0은 DOTA-v1.0보다 더 작은 인스턴스를 가지고 있으며 DOTA-v2.0에서는 약 10 픽셀의 일부 인스턴스에 주석을 달았다.
AR은 Faster R-CNN [53] 및 You Only Look Once (YOLOv2) [50]와 같은 앵커 기반 모델에 필수적이다. 해당 연구진들은 기존 OBB의 AR과 OBB를 통해 축 정렬 바운딩 박스를 계산하여 생성되는 HBB의 AR을 사용하는 모델 설계를 안내한다.

위의 FIgure6은 DOTA에서 이런 ARs 분포를 보여주며 ARs 비율이 상당히 다르다는 것을 알 수 있다.
이미지 당 인스턴스 수는 object detection 데이터 셋에 중요한 속성이다. 밀도가 매우 높거나(이미지 패치 당 최대 1000개의 인스턴스) 매우 희박(이미지 패치 당 하나의 인스턴스만 존재)할 수도 있다. DOTA의 이미지 당 인스턴스 수는 자연 이미지 데이터셋 보다 훨씬 더 다양하다.
카테고리 마다 밀도 분포 역시 다르며 각 인스턴스에 대해 동일한 범주에서 가장 가까운 인스턴스까지의 거리를 먼저 측정한 후 거리를 밀도 [0,10], 정규 [10, 50) 및 희소(50, inifinity]의 세 부분으로 나눈다.

5. Benchmarks
object detection은 이미지에서 인스턴스를 찾아 분류하는 것이다. 해당 논문은 두 개의 위치 표현을 사용한다. 하나는 HBB로 직사각형 영역(rectangular region), $$ (x,y,w,h) $$ 다른 하나는 OBB로 oriented 직사각형 영역(oriented rectangular region) $$ (x,y,w,h,\Theta) $$이다.
이전 벤치마크 알고리즘은 DOTA에서 비교하기 어렵기 때문에 해당 논문은 MMDetection에서 수정된 단일 코드 라이브러리에서 모든 알고리즘을 구현하고 평가한다.
메모리 제한으로 인해 큰 이미지를 CNN에 사용할 수 없기 때문에 stride가 824로 설정된 원본 이미지에서 1024x1024 패치를 자른다. 예측 중 임시 결과를 얻기 위해 학습과 동일한 설정을 한 패치를 보내어 패치 좌표에서 detection된 결과를 원본 이미지 좌표에 매핑한 후 NMS를 적용한다.
해당 연구진들은 HBB 실험일 경우 NMS 임계값을 0.3으로, OBB 실험일 경우 0.1로 설정했다. 다중 스케일 훈련 및 테스트의 경우 먼저 원본 이미지를 [0.5, 1.0, 1.5]로 확장한 후 이미지를 1024x1024 크기의 패치와 824 stride로 잘른다. 총 배치 크기가 8(GPU 당 이미지 2개)인 학습을 위해 4개의 GPU를 사용한다. 학습률은 0.01로 설정되어 있으며 "2X"를 채택하는 RetinaNet을 제외한 다른 알고리즘은 "1X' 학습을 채택한다. 다른 매개 변수들은 Detectron의 매개 변수를 따른다.
HBB를 사용하여 베이스 라인을 구축하는 방법에는 2가지가 있다. 첫번째 방법은 HBB 결과를 직접 예측하는 것이고 두번째 방법은 OBB 결과를 먼저 예측한 후 OBB를 HBB로 변환하는 것이다. HBB 결과를 직접 예측하기 위해서 RetinaNet, Mask R-CNN, Hybrid Task Cascade, Faster R-CNN을 베이스 라인으로 사용한다.
OBB를 사용하여 베이스 라인을 구축하는 방법은 두가지가 있다. 첫번재는 HBB Head를 OBB Head로 변경하는 방법으로 이는 HBB에 대한 OBB의 오프셋을 회귀시킨다. 두 번째는 마스크 헤드(Mask Head)로, OBB를 coarse한 마스크로 간주하고 각 RoI에서 픽셀 수준 분류를 예측하는 방법이다.
OBB Head - OBB를 예측하기 위해 Faster R-CNN과 Textbox++는 각각 Faster R-CNN의 RoI Head와 SSD(single-shot detector)의 Anchor Head를 수정하여 사각형(quadrangles)을 회귀시켰다. 해당 논문에서는 OBB 회귀를 위해 $$ {(xi, yi)|i = 1,2,3,4} $$ 대신 $$ (x,y,w,h,\Theta) $$ 표현을 사용한다. Faster RCNN의 HBB RoI Head와 RetinaNet의 Anchor Head를 OBB Head로 교체하고 Faster R-CNN OBB와 RetinaNet OBB라는 두가지 모델을 얻는다. 또 Mask R-CNN과 유사한 HBB와 OBB를 병렬로 예측하도록 Faster R-CNN을 수정한다. 이런 모델을 Faster R-CNN H-OBB라고 부른다. Faster R-CNN OBB에서 RoI 정렬을 대체하여 deformable RoI pooling (Dpool)r과 RoI Transformer를 추가로 평가한다.
Mask Head - Mask R-CNN은 원래 분할에 사용되었다. DOTA에는 각 인스턴스에 대한 픽셀 수준의 주석이 없지만, OBB 주석을 픽셀 수준의 주석으로 간주할 수도 있기 때문에 DOTA에 Mask R-CNN을 적용할 수 있다. 예측 중에는 예측 Mask를 포함하는 최소 OBB를 계산한다. 이미지 당 인스턴스의 수가 많으면 NMS 이후의 모든 HBB에 Mask Head를 적용한다. 이런 방법으로 Mask R-CNN, Cascade Mask R-CNN, Hybrid Task Cascade을 평가한다.
해당 논문에서는 object detection 라이브러리로 https://github.com/dingjiansw101/AerialDetection 와 개발 키트인 https://github.com/CAPTAIN-WHU/DOTA_devkit 를 소개한다.
MMDetection에는 object detection 알고리즘이 많이 있으며 모듈식 설계 기능이 있기 대문에 이를 기본 코드 라이브러리로 선택했다. 하지만 oriented object detection을 지원하는 모듈이 없기 때문에 OBB를 예측 가능하게 하기 위해 OBB Head로 MMDetection을 늘렸다. 또한 rotated region feature를 추출하기 위해 rotated RoI Align 및 rotated position sensitive RoI Align과 같은 모듈을 구현했다.
6. Results
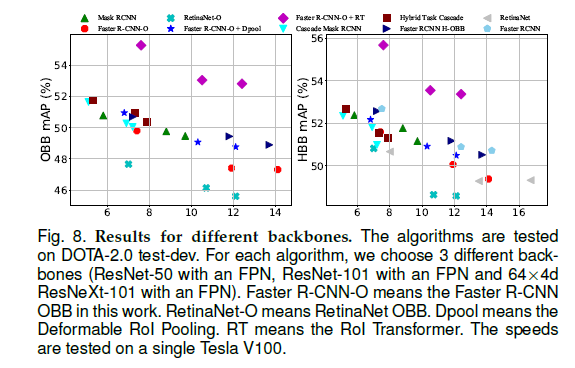
해당 절에서는 70개가 넘는 실험에 대한 종합적인 평가를 실시하고 그 결과를 분석한다. DOTA의 속서을 탐색하고 향후 연구를 위해 모듈 설계와 하이퍼파라미터 설정을 평가한다 그 후 데이터 확대의 영향을 자세히 분석하여 ODAI의 어려움을 보여주기 위해 아래 Figure9와 같이 결과를 시각화한다.
Mask Head vs OBB Head - OBB Head는 oriented object detection을 회귀 문제로 처리하는 반면 Mask Head는 필셀 수준 분류 문제로 처리한다. Mask Head는 더 쉽게 수혐하고 더 나은 결과를 달성하기는 하지만 계산 비용이 훨씬 많이 든다.
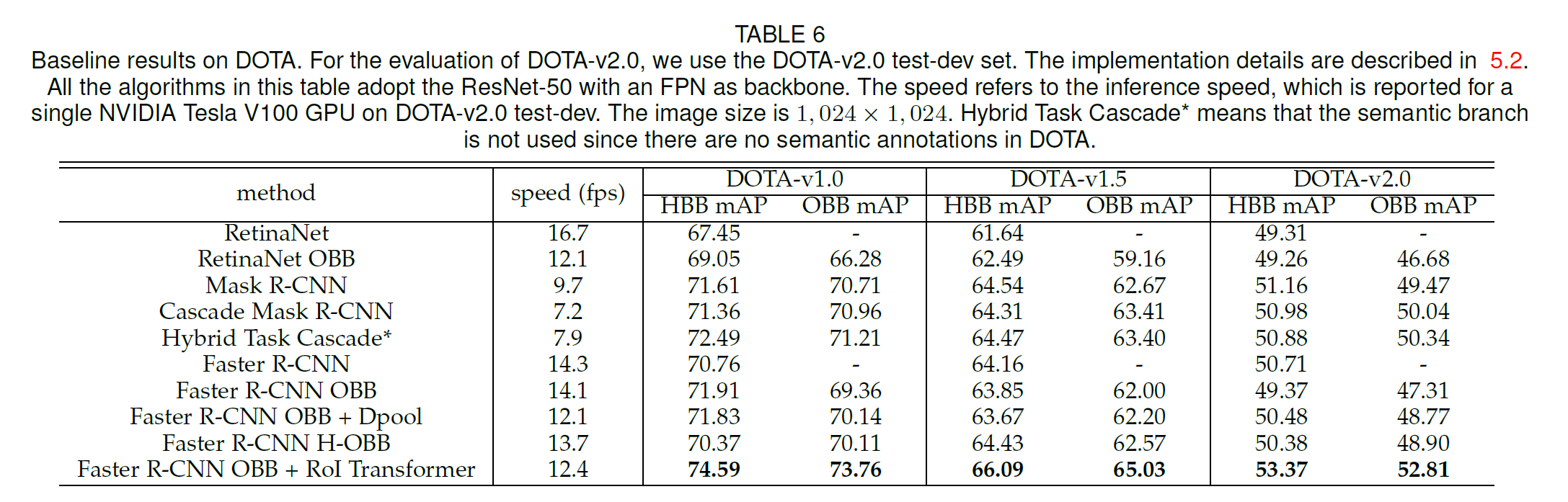
RoI Transformer vs. Deformable RoI Pooling - Faster R-CNN OBB에서 RoI 정렬을 대체하여 RoI Transformer와 Dpool을 평가한다. 아래 표6과 Figure8은 Dpool이 대부분 Faster R-cNN OBB의 성능을 향상시키는 반면 RoI Transformer는 Dpool 보다 성능이 우수하다는 것을 보여준다. 이 결과는 RoI Transformer와 같이 신중히 설계된 geometry 변환 모듈이 항공 이미지용 Dpool과 같은 일반 geometry 변환 모듈보다 낫다는 것을 의미한다.
Excluding Smaal Instances - DOTA-v1.5 및 DOTA-v2.0에 대한 훈련 중 아주 작은 인스턴스들이 수치 불안정성을 야기할 수 있기 때문에 DOTA-v1.5 및 DOTA-v2.0 실험의 경우 너무 작은 인스턴스를 제외하는 임계값을 설정했다. 아주 작은 인스턴스를 2가지 기준으로 필터링을 한다. 첫번째로 인스턴스 영역이 특정 임계값 미만일 때이다. 두번째로는 max(w,h)가 임계값 미만일때 이다. 여기서 w와 h는 각각 해당 HBB의 폭과 높이이다.
Number of Proposals - 앞에서 언급했듯이 항공 이미지에서 수용 가능한 인스턴스 수는 자연 이미지에서와 아주 다르다. DOTA에서는 하나의 1024x1024 이미지에서 1000개 이상의 인스턴스가 포함될 수 있다. Faster R-CNN OBB + RoI Transformer에 대한 선능이 가장 높은 proposal의 수는 8000개이다. proposal의 수가 증가하면서 더 많은 계산이 이루어 지므로 해당 논문의 다른 실험에서는 2000개의 proposal을 선택한다. DOTA의 최적 number of porpsals은 300이다. 이러한 결과는 항공 이미지와 자연 이미지 사이의 차이가 크다는 것을 확인시켜주는 것을 의미한다.
Data Augmentation - 해당 연구진들은 데이터 Augmentation의 영향을 살펴보았다. 사용한 모델은 Faster R-CNN OBB + RoI Transformer이다. backbone으로 R-50-FPN을 선택하여 5가지 Data Augmentation 전략을 채택했다.
1. 큰 인스턴스는 가장자리에서 잘릴 수 있으므로 패치 간의 오버랩을 200에서 512로 변경한다.
2,3. 원본 이미지의 크기를 [0.5, 1.0, 1.5]로 조정한 후 원본 이미지를 1024x1024의 패치로 자른다.
4. roundabouts와 storage tanks가 있는 이미지의 경우 패치를 $$ [\pi/2, \pi, -\pi/2, -\pi] $$네 각도로 무작위로 회전시킨다. 다른 범주가 있는 이미지의 경우 훈련 중 $$ [-\pi, \pi] $$ 범위에서 무작위로 각도를 회전시킨다.
5. 테스트 중 augmentation은 이미지를 4개의 각도 ($$ [0, \pi/2, \pi, 3\pi/2] $$)로 회전시킨다.
이런 스케일 및 augmentation 데이터는 object detection 성능을 향상키시며 이는 DOTA의 큰 스케일 및 방향 변화와 일치한다.

위의 Figure9에서 Faster R-CNN, Faster R-CNN OBB, RetinaNet OBB, Mask R-CNN, Faster R-CNN OBB + RoI Transformer 성능을 비교하여 나타내고 있다.
첫번째 줄에서는 대형 차량이 빽빽하게 모여있다. Faster R-CNN은 HBB에서 인접한 대형 차량 간의 높은 중복으로 인해 대부분의 인스턴스를 놓치는 것을 볼 수 있다. 이러한 대형 차량은 NMS를 통해 컨트롤된다. Faster R-CNN OBB, Mask R-CNN, Faster R-CNN OBB + RT는 성능이 우수한 반면 RetinaNet OBB는 제대로 정렬이 되지 않아 위치 정밀도가 낮다.
두번째와 세번째 줄에서는 ARs가 큰 긴 형태의 object를 나타내고 있다. 이러한 인스턴스는 부분이 전체 인스턴스와 유사한 기능을 가지고 있다. 이는 하나의 object에 대해서도 최소 2개의 예측이 있다는 것을 의미한다. 서로 다른 범주임에도 특징이 매우 유사하기 때문에 다리는 공항과 항구로 분류되기도 하며 선박은 항구와 다리로 분류되기도 한다.
마지막 줄은 아주 작은 인스턴스를 검출하는데 있어 어려움을 보여주고 있다. 이는 약 10 픽셀 미만의 인스턴스가 해당하며 recall은 아주 낮다.
7. Conclusion
ODAI는 도전적이며 해당 논문은 향후 연구를 위해 OBB로 주석을 단 대규모 데이터셋인 DOTA를 소개한다. 또 oriented과 horizontal ODAI 모두를 위한 코드 라이브러리를 구축하여 종합적인 평가를 수행한다. 이러한 실험이 ODAI 알고리즘 간의 공정한 비교를 위한 벤치마크 역할을 할 수 있기를 바란다.
실험 결과는 항공 이미지에 대한 알고리즘의 매개 변수 선택 및 모둘 설계가 자연 이미지와는 아주 다르다는 것을 보여주고 있으며 이는 DOTA를 자연 이미지의 보충물로 사용하여 object detection을 용이하게 할 수 있음을 암시하고 있다.
논문을 읽은 후 주관을 가지고 요약, 정리한 글이므로 해당 포스팅에 대한 이의 제기, 다른 의견 제시 등 다양한 지적, 의견은 언제나 대환영입니다!
댓글로 남겨주시면 늦더라도 확인하겠습니다!!!