
메타코드 정처기 필기 3강
[40% 최대 할인 / 25.01.06까지] 2025 정보처리기사 필기 합격 올인원ㅣ기출문제 풀이 포함
www.metacodes.co.kr
3강 - 절차형 SQL 작성
◼️ SQL 응용
▪️ SQL (Structured Qurery Language)
- 데이터베이스에서 데이터를 추출하고 조작하기 위해 사용하는 데이터 처리 언어
- 대량의 데이터를 빠르게 조회, 필터링, 집계할 수 있어 데이터 분석 작업을 신속히 수행 가능
- 대부분 데이터베이스 시스템에서 사용하는 표준화된 언어로 활용이 편리
▪️ 스키마(Schema)
- 데이터베이스 객체들을 논리적으로 그룹화하는 데이터 구조
▪️ 외부 스키마
- 사용자나 응용 프로그램이 데이터를 보는 관점
- 특정 사용자의 요구에 맞춘 사용자 뷰를 제공
▪️ 개념 스키마
- 데이터베이스 전체의 논리적 구조를 정의
- 테이블, 뷰, 인덱스, 관계 및 제약 조건을 포함한 모든 데이터베이스 객체를 정의
▪️ 내부 스키마
- 데이터베이스의 물리적 저장 구조를 정의
- 데이터 파일의 저장 위치, 접근 경로 등을 포함
▪️ DDL 명령어 종류 : CREATE, ALTER, DROP, TRUNCATE
- CREATE : 데이터베이스 객체(도메인, 스키마, 테이블, 인덱스, 뷰)를 생성하는 명령어

- PRIMARY KEY : 테이블의 기본 키를 저으이
- UNIQUE : 해당 컬럼에는 고유한 값만 들어오게 하는 제약 조건
- FOREIGN KYE : 외래 키를 정의
- CONSTRANINTS ~ CHECK : 제약 조건
- ALTER : 기존의 데이터베이스 객체를 수정하는 명령어

- DROP : 데이터베이스 객체를 삭제하는 명령어

- CASCADE : 테이블을 참조하는 모든 객체도 함께 삭제
- RESTRICT : 테이블이 다른 객체에 의해 참조되고 있으면 삭제되지 않음(기본 옵션)
- TRUNCATE : 테이블의 모든 데이터를 삭제하지만, 테이블의 구조는 유지하는 명령어
▪️ DCL의 명령어 종류 : GRANT, REVOKE, COMMIT, ROLLBACK, SAVEPOINT
- GRANT : 특정 사용자 또는 사용자 그룹에게 데이터베이스 객체에 대한 권한을 부여
- GRANT SELECT ON "직원 정보" TO "USER1";
- GRANT SELECT ON "직원 정보" TO "USER1" WITH GRANT OPTION;
- REVOKE : 부여된 권한 회수
- REVOKE UPDATE ON "직원 정보" FROM "USER1";
- REVOKE UPDATE ON "직원 정보" FROM "USER1" CASCADE;
- COMMIT : 트랜잭션에서 수행된 작업을 영구적으로 데이터베이스에 적용
- ROLLBACK : 트랜잭션에서 수행된 작업을 취소하고 이전 상태로 되돌림
- SAVEPOINT : 트랜잭션 내에서 중간 지점을 설정하여 부분 취소를 가능하게 함
▪️DML 명령어 종류 : SELECT, INSERT, UPDATE, DELETE
- SELECT : 데이터 조회
- INSERT : 데이터 입력
- UPDATE : 데이터 변경
- DELETE : 데이터 삭제
◼️ SQL 활용
▪️ 트랜잭션
- 데이터베이스 관리 시 시스템에서 수행되는 일련의 작업들을 하나의 단위로 묶은 것
▪️트랜잭션의 특성 (ACID)
- Atomicity(원자성) : 트랜잭션 내의 모든 작업이 모두 수행되거나 모두 수행되지 않아야 함
- Consistency(일관성) : 트랜잭션이 시작되기 전과 완료된 후에 데이터베이스의 상태는 규칙에 맞게 일관되어야 함
- Isolation(고립성, 격리성) : 여러 트랜잭션이 동시에 실행될 때 트랜잭션 간 서로 영향을 미칠 수 없음
- Durability(지속성) : 트랜잭션이 성공적으로 완료되면 그 결과는 영구적으로 데이터베이스에 저장되어야 함
▪️ 트랜잭션의 상태

- Active : 트랜잭션이 시작되어 작업을 수행 중인 상태
- Partially Committed : 모든 작업을 수행하였지만 결과를 한번에 DB에 반영하지 않은 상태
- Committed : 트랜젹선이 성공적으로 완료되어 데이터베이스에 모든 변경 사항이 영구 저장된 상태
- Failed : 트랜잭션이 더이상 정상적으로 진행될 수 없을 때의 상태
- Aborted : 트랜잭션이 취소되고 Rollback 연산이 실행되어 시작 전 상태로 돌아감
▪️ 병행 제어
- 트랜잭션 간 충돌을 방지하고 데이터베이스가 항상 일관된 상태를 유지하도록 하는 것
- 데이터베이스 공유 최대화, 시스템 활용도 최대화, 데이터베이스 일관성 유지, 사용자에 대한 응답시간 최소화
▪️병행 제어 기법
- 로깅(Locking), 타임스탬프, 낙관적 검증(Optimistic Validation), 다중버전 동시성 제어(MVCC), 2 Phase Commit
▪️ 트랜잭션 회복 기법
- 지연 갱신 회복기법, 즉각 갱신 회복기법, 체크포인트 회복기법, 그림자 페이징 회복기법,
▪️ 뷰(View)
- 실제 데이터를 저장하지 않고 쿼리 결과를 동적으로 생성하는 가상의 논리적 테이블
- 데이터 접근 제어를 통해 데이터의 논리적 독립성과 보안 제공
- 사용자 요구에 맞게 데이터를 제공할 수 있어 사용자 데이터 관리 용이
- 뷰 위에 다른 뷰 정의 가능
- Insert, Update, Delete 연산 및 인덱스 생성에 제약사항 따름
- Create문을 사용해 정의하고 Drop문을 통해 제거
▪️인덱스(Index)

- 데이터 검색 시 처리속도 향상에 도움
- 테이블 삭제 시 인덱스도 같이 삭제
- 기본 테이블처럼 Create 문 사용해 정의하고 Drop문 통해 제거
▪️ 집한 연산

- 두 개 이상의 쿼리 결과를 결합하거나 비교하는 연산
- 집합 연산 수행 시에는 각 쿼리 결과의 열 개수와 데이터 유형이 일치해야 함
▪️ 조인(Join)
- 두개 이상의 테이블을 연결해 데이터를 결합하는 방법
- 내부 조인(Inner Join) : 두 테이블 간에 공통된 값이 있는 행만 결합해 반환, 일치하는 데이터만 조회되므로 양쪽 테이블 모두에 있는 값만 결과에 포함됨.
- 외부 조인(Outer Join) : 매칭되지 않는 행은 NULL이 반환
- Left Outer Join : 왼쪽 테이블의 모든 행을 반환하고 오른쪽 테이블에서 일치하는 데이터를 함께 반환
- Right Outer Join : 오른쪽 테이블의 모든 행을 반환하고 왼쪽 테이블에서 일치하는 데이터를 함께 반환
- Full Outer Join : 두 테이블의 모든 데이터를 반환
- Self Join : 한 테이블을 스스로와 조인하는 방식으로 같은 테이블 내에서 데이터를 조합할 때 사용
◼️ 논리 데이터베이스 설계
▪️관계 데이터 모델
- 데이터를 테이블 형식으로 정리하여 저장하고 각 테이블이 서로 관계를 맺도록 하는 데이터베이스 모델
- Relation, Tuple, Attribute, Cardinality, Degree, Schema, 인스턴스, 식별자, 도메인 등
▪️ 릴레이션 (Relation)
- 행과 열로 구성된 테이블
- 한 릴레이션에 포함된 튜플은 모두 상이함
- 릴레이션에 포함된 튜플 사이에는 순서가 없음
▪️ 튜플 (Tuple)
- 릴레이션의 행, 튜플의 수를 Cardinality라고 함
▪️애트리뷰트 (Attribute)
- 릴레이션의 열 = 특성 = 속성 = 필드
- 개체의 특성을 기술
- 데이터베이스를 구성하는 가장 작은 논리적 단위
- 애트리뷰트의 수를 degree로 표현
▪️ 관계 대수
- 관계형 데이터베이스를 다루는 수학적 연산 체계로 데이터베이스 검색에 대한 이론적 기반
- 절차적 언어로 일반 집합 연산과 순수 관계 연산으로 구분
▪️ 관계대수 연산 - 일반 집합 연산자
- 합집합(Union, U), 교집합(Intersection, ∩), 차집합(Difference, -), 카르테시안 곱(Cartesian Product, X)
▪️관계때수 연산 - 순수 관계 연산자
- 셀렉트(σ), 프로젝트(π), 조인(⨝), 디비전(÷)
▪️ 데이터 모델
- 데이터베이스 시스템에서 데이터를 체계적으로 관리하고 조작할 수 있도록 하는 개념적인 프레임워크
- 개념적, 논리적, 물리적 모델로 설명할 수 있음
- 구조(Structure), 연산(Operation), 제약조건(Constraint)가 표시되어야 함
- 설계 순서 : 요구사항 분석 -> 개념적 설계 -> 논리적 설계 -> 물리적 설계 -> 구현
▪️ 개체-관계 다이어그램(E-R Diagram)
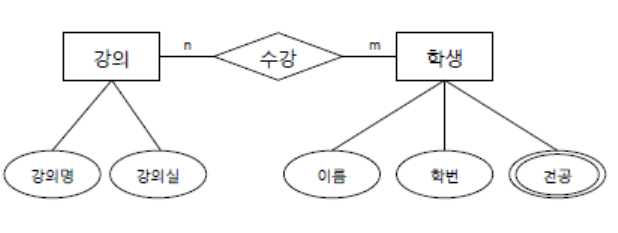
- 개체(Entity) : 데이터베이스에 저장되는 객체를 의미, 사각형으로 표기
- 속성(Attribute) : 개체의 특성을 의미, 타원형으로 표기
- 다중값 속성(Multi-valued Atttribute) : 한 속성이 여러 값을 가질 수 있으면 이중 타원으로 표기
- 관계(Relationship) : 두개 이상의 개체 간 관계를 표현, 마름모로 표기
- 관계-속성 연결 : 선으로 표현
▪️ 데이터 모델의 논리적 설계
- 개념적 설계를 바탕으로 데이터베이스를 논리적 구조로 변환
- 트랜잭션 인터페이스 설계
▪️ 데이터 모델의 물리적 설계
- 논리적 설계를 기반으로 데이터 저장 방식을 효율적인 방식으로 최적화
- 저장 레코드 형식, 순서, 데이터 값의 분포, 접근 경로, 접근 빈도와 같은 정보를 사용해 설계
- 레코드 집중의 분석 및 설계
▪️ 정규화
- 데이터베이스 설계 시 데이터를 구조화하여 중복을 최소화하고 데이터 무결성을 보장하는 과정
- 데이터 구조의 안정성을 최대화 함
- 중복을 최소화하여 삽입, 삭제, 갱신 이상의 발생을 방지
- 데이터 삽입 시 릴레이션을 재구성할 필요를 줄임
- 테이블 불일치 위험 최소화
- 효과적인 검색 알고리즘을 생성할 수 있음
▪️ 제1정규형(1NF)

- 어떤 릴레이션에 속한 모든 도메인이 원자값만으로 되어 있음
- 각 컬럼에는 단일 값만 포함되어야 함
▪️제2정규형(2NF)
- 제1정규형을 만족하면서 부분함수 종속성 제거
▪️ 제3정규형(3NF)
- 제2정규형을 만족하면서 이행함수 종속성 제거
▪️ Boyce Codd 정규화(BCNF)
- 제3정규형을 만족하면서 결정자가 후보 키가 아닌 함수 종속 제거
▪️ 제4정규형(4NF)
- BCNF를 만족하면서 다치 종속성을 제거
▪️ 제5정규형(5NF)
- 4NF를 만족하면서 후보키를 통하지 않는 조인 종속 제거
◼️ 물리 데이터베이스 설계
▪️ 분산 데이터베이스 시스템
- 실제 지리적으로 분산된 데이터베이스들을 관리하고 통합하여 단일 시스템처럼 작동하도록 만드는 시스템
- 투명성을 위한 효율적인 설계 필요
▪️ 투명성
- 분산 데이터베이스의 목표로 사용자가 데이터가 물리적으로 어디에 있는지 알 필요 없이 시스템을 사용하도록 하는 개념
- 장애 투명성(Failure Transparency) : 특정 지역의 시스템이나 네트워크에 장애가 발생해도 데이터 무결성이 보장됨
- 위치 투명성(Location Transparency) : 사용자가 데이터의 실제 저장위치를 알 필요 없이 데이터에 접근할 수 있도록 함
- 복제 투명성(Replication Transparency) : 동일한 데이터가 여러 위치에 복제되어 있는 경우 사용자가 인식하지 못하도록 함
- 분할 투명성(Fragmentation Transparency) : 데이터가 여러 조각으로 나뉘어 분산되어 있는 경우에도 사용자가 이를 인식하지 못하도록 함
- 병행 투명성(Concurrency Transparency) : 여러 사용자가 동시에 데이터에 접근했을 때 발생할 수 있는 문제를 인식하지 못하도록 함
▪️ 파티셔닝 기법
- 대용량의 데이터를 파티션이라는 작은 논리 단위로 나누어 성능을 최적화 하는 것
- 물리적 파티셔닝으로 전체 데이터 훼손 가능성은 줄고 데이터 가용성이 향상됨
- 범위 분할(Range Partitioning), 목록 분할(List Partitioning), 해시 분할(Hash partitioning), 조합 분할(Composite Partitioning), 라운드 로빈(Round Robin)
▪️ 슈퍼 키(Super Key)
- 한 릴레이션 내의 속성들의 집합으로 구성된 키
- 릴레이션을 구성하는 모든 튜플에 대한 유일성은 만족시키지만 최소성은 만족시키지 못하는 키
▪️ 후보 키(Candidate Key)
- 릴레이션 후보키는 유일성과 최소성을 만족해야 함
- 모든 릴레이션은 반드시 하나 이상의 후보 키를 가짐
▪️ 기본 키(Primary Key)
- 릴레이션에서 각 레코드를 고유하게 식별하는 키
- Not NULL 제약조건을 기본으로 포함하고 있어 NULL 값을 가지지 않음
- 외래 키로 참조될 수 있음
▪️ 대체 키(ALternate Key)
- 후보키 중 기본키로 선택되지 않은 나머지 키
▪️ 외래 키(Foreign Key)
- 다른 릴레이션의 기본 키를 참조하는 키
- 외래 키는 참조하는 테이블의 기본 키와 동일한 값이어야 함
- 외래 키는 NULL일 수 있음
▪️ 데이터베이스 무결성
- 데이터베이스에 저장된 데이터가 정확하고 일관되며 신뢰할 수 있는 상태를 유지하도록 보장하는 원칙
- 무결성 규정의 대상으로는 도메인, 키, 종속성 등이 있음
- 개체 무결성 : 한 릴레이션의 기본키를 구성하는 어떠한 속성값도 NULL이나 중복값을 가질 수 없음
- 참조 무결성 : 외래 키는 다른 테이블의 기본 키를 참조하며 참조된 기본 키 값과 동일하거나 NULL이어야 함
- 속성 무결성 : 속성의 기본값, 데이터 타입 등 지정된 규칙을 준수해야 함
- 관계 무결성 : 관계를 조작하는 과정에서의 의미적 관계를 명세
▪️ 반정규화
- 데이터베이스 성능 향상을 위해 이미 정규화된 데이터 구조를 일부러 중복하거나 합쳐서 복잡성을 줄이는 과정
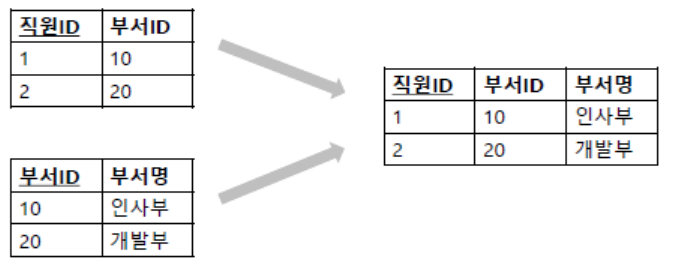
- 집계 테이블 추가
- 진행 테이블 추가
- 특정 부분만 포함하는 테이블 추가
◼️데이터 전환
▪️ ETL(Extract, Transform, Load)
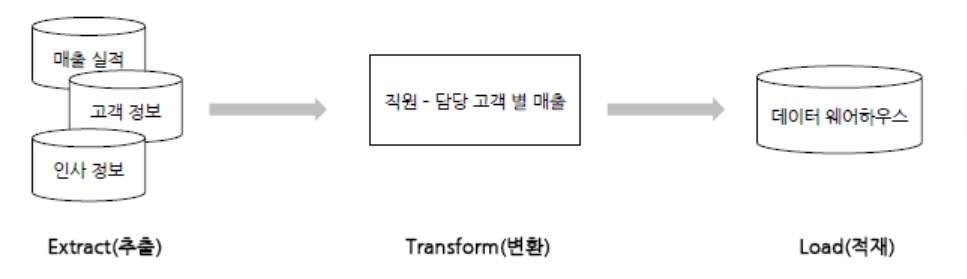
- 데이터를 추출-변환-적재하는 데이터 처리 과정
- 여러 출처에서 데이터를 수집하여 원하는 형태로 변환한 뒤 데이터 웨어하우스나 데이터베이스에 저장
메타코드에서 정보처리기사 필기 강의 장학생으로 선발되어 앞으로 5주간 메타코드에서 정처기 필기 강의를 듣고 포스팅을 하게 되었다.
현재 메타코드에서는 정보처리기사 필기 환급 챌린지를 진행 중이며 합격 인증 시 100% 환급(제세공과금 22%, 교재비 3만원 제외)을 해 준다.
진도율을 100% 달성하고 시험 합격 후 합격 인증, 후기 작성 시 수강료를 100% 환불 (제세공과금 22%, 교재비 3만원 제외)을 해주기 때문에 수강료 부담없이 정처기 자격증을 따고 싶은 사람에게 좋은 강의이다.
https://metacodes.co.kr/edu/read2.nx?M2_IDX=31635&EP_IDX=15203&EM_IDX=15027
정보처리기사 필기 환급 챌린지ㅣ합격 인증 시 100% 환급 (제세공과금 22% 제외)
metacodes.co.kr