

Quasi-Dense Similarity Learning for Multiple Object Tracking, Jiangmiao Pang, et al., 2021을 읽고 요약한 글입니다.
논문을 읽고 이해하면서 정리를 한 글이기에 논문 내의 contents 순서와 해당 포스팅의 목차 순서는 다른 것임을 미리 명시합니다.
정리에 앞서 논문을 읽으면서 따로 단어를 정리해 둔 것이 있어서 함께 작성한다.
dense matching : 모든 픽셀에서 box 후보 간에 일치하도록 정의함.
quasi-dense : 정보 영역에서 잠재적 객체 후보만 고려하는 것을 의미함.
sparse matching : 객체 연결을 학습할 때 ground truth 레이블만 일치하는 후보로 간주한다는 것을 의미함.
image pair에 대한 수백 개의 region proposal에서 인스턴스 similarity를 학습하고, multiple positive contrastive 학습으로 feature 임베딩을 학습함. feature space에서 가장 가까운 simple nearest neighbor search를 통해 인스턴스를 구별할 수 있음.
기존 detection에 의존해서 tracking을 하던 방법은 화면 속에서 객체가 겹치거나 사라지게 될 때는 tracking을 제대로 하지 못하는 문제가 있다. 따라서 객체가 제대로 검출이 되면 인스턴스를 연관 짓고 구별하는 것이 중요하다.
기존 tracking 방법들은 아래와 같다.
1. Location and motion in MOT
: 칼만 필터, optical flow 및 displacement regression와 같은 일부 방법은 정확한 거리 추정을 보장하기 위해 motion priors를 사용하는 반면에 Detect & Track은 연속 프레임에서 객체의 변위(displacements)를 예측하고 객체를 Viterbi 알고리즘과 연관 시킨다. 하지만 이 또한 사라진 객체를 다시 식별하기 위해 추가 재 식별 모델이 여전히 필요하다. 연속적인 프레임에서 물체를 연관 시키는데 효과적이지만, 사람이 많은 군중과 같은 복잡한 프레임에서는 tracking이 잘 되지 않았다.
2. Appearance similarity in MOT
: 이미지 similarity learning으로 인스턴스 모양(외관?)을 학습하는데 n 클래스 분류 문제로 학습함(n은 전체 학습 데이터셋의 ID 수와 같다. 이는 대규모 데이터셋으로 확장하기 어렵고 각 train sample과 다른 두 개의 ID만 비교하기 때문에 MOT에서 인스턴스 similarity learning이 완전히 explored(탐구, 분석)되지 않았다. 따라서 인스턴스의 모양 similarity는 부차적인 역할만 한다. 인스턴스 모양(외관?)유사성을 이용해서 tracking을 강화하였으며 사라진 객체를 재 식별하기 위해 independent 모델을 직접 사용하거나 end-to-end 학습 위해 detector에 extra embedding head를 추가했다.
3. Contrastive learning
: Contrastive learning은 MOT에서 인스턴스 similarity learning에서 큰 관심을 끄진 못했는데 multi positive contrastive learning와 함게 quasi-dense samples로 매치된 dense를 supervise한다. 이는 positive target이 하나만 있을 때만 처리가 가능하다.
QDtrack은 dense하게 연결된 contrastive pairs로부터 인스턴스 similarity를 학습하고 feature space를 단순한 가장 가까운 이웃 search와 연관 시키면서 성능은 더 높히고 프레임워크는 더 단순하게 함으로써 MOT에서 quasi-dense similarity learning의 힘을 증명한다.
MOT에 quasi-matching을 사용하는 주요 요소는 객체 detection, 인스턴스 similarity learning및 객체 연관성이다.
1. Object Detection - Faster R-CNN with Feature Pyramid Network

QDtrack은 기존 detector와 end-to-end 학습과 결합할 수 있으며 조금의 수정으로 다른 detector를 적용할 수도 있다. FPN을 예로 들면, faster R-CNN Feature 피라미드 네트워크에서 Faster R-CNN은 RoI를 생성하는 RPN(Region Proposal Network)을 사용하는 two stage detector인데, 이는 semantic label과 semantic locations을 포함하는 regions을 localizion하고 clasiification한다. Faster R-CNN을 base로 해서 FPN은 top-down feeatruel 피라미드와 scale-variance 문제인 tackles를 build하기 위해 lateral connections을 이용한다.
전체 네트워크는 RPN 손실(Lrpn), 분류 손실(Lcls), 회귀 손실(Lre)이 원래 논문과 동일하게 유지되는 다중 작업 손실 함수 (Eq 1) Ldet = Lrpn + λ1Lcls + λ2Lreg로 최적화 된다.

손실 가중치 λ1과 λ2는 기본적으로 1.0으로 설정되어 있다.
quasi-dense 샘플은 이미지에서 대부분의 정보 영역을 커버 할 수 있고 더 많은 box sample과 hard negative를 제공하기 때문에 contrastive laerning을 위해 한 쌍의 이미지에서 수백 개의 RoI를 조밀하게(dense) 매칭하는 quasi-dense similarity learning을 제안한다.
2. Instance Similarity Learning

RPN에 의해 생성된 region proposals을 사용하여 quasi-dense matching과 인스턴스 유사성을 학습한다.
위 그림과 같이, 학습을 위한 key 이미지 Frame1이 주어지면 temporal neighborhood에서 기준 이미지 Frame2를 무작위로 선택한다.
neighbor 거리는 간격 k에 의해 제한되며, 여기서 k ∈ [-3, 3]으로 제한함. RPN을 사용하여 두 이미지에서 RoI를 생성하고 RoI Align을 사용하여 척도에 따라 FPN의 서로 다른 수준에서 기능 맵을 얻는다. 각 RoI에 대한 기능을 추출하기 위해 원래 bbox head와 병렬로 추가되는 초경량 embedding head를 추가한다. RoI는 물체의 IoU가 α1보다 높으면 양수로 정의되고, α2보다 낮으면 음수로 정의한다. α1과 α2는 실험에서 0.7과 0.3이며 두 프레임에서 RoI의 일치는 두 영역이 동일한 객체와 연관되어 있고 연관되어 있지 않으면 음수이다.
key prame에 학습용 샘플로 V 샘플이 있고, 기준 프레임에 대조적인 타겟으로 K 샘플이 있다고 가정하면, 각 훈련 샘플에 대해 cross-entropy를 가진 non-parametric softmax를 사용하여 특징 임베딩(Eq 2)을 최적화할 수 있다.

여기서 v, k+, k-는 학습 샘플, positive target 및 K의 negative targets의 특징 임베딩으로 전체 embedding loss는 모든 학습 샘플에서 평균화 된다.
이미지 쌍(pair)에 RoI 간 dense matching을 적용한다. Frame1의 각 샘플은 Frame2의 모든 샘플과 일치하며, 이는 이전 연구에서 인스턴스 유사성을 학습하기 위해 주로 ground truth bbox인 sparse 샘플 crops만 사용하는 것과 대조적이다. 키 프레임의 각 학습 샘플은 기준 프레임에 하나 이상의 positive target을 가지고 있으므로, Eq(2)는 Eq(3)과 같이 확장될 수 있다.

그러나 이 방정식은 positive target과 negative target을 공평하게 다루지 않는다. 즉, 각각의 negative target은 여러 번 고려되지만 positive target에 대해서는 한 번만 고려됨. 또는 먼저 식 Eq(2)를 Eq(4)로 재구성할 수 있다.
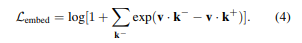
그렇다면 multi-poisitive scenario에서는 Eq (5)와 같이 positive 항을 누적하여 확장할 수 있으며 또, L2 loss를 auxiliary loss (Eq. 6)로 채택했다.
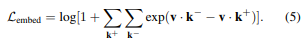

여기서 두 표본의 일치가 양수이면 c가 1이고 그렇지 않으면 0이다. auxiliary loss가 성능을 향상시키는 대신 logit magnitude와 코사인 유사성을 제한하는 것을 목표로 한다.

전체 네트워크는 Eq(7)에 따라 joint 최적화되었으며, 해당 논문에서는 기본적으로 γ1과 γ2가 0.25와 1.0으로 설정되어 있다. auxiliary loss를 계산하기 위해 모든 positive pair와 세 배 더 많은 negativie pair를 샘플링했다.
MOT는 similarity말고도 FP, ID switches, 새로 나타난 객체, 사라진 객체도 고려해야 한다.
similarity metric으로 누락된 대상을 해결하기 위해 bi-directional softmax를 사용하여 bi-directional consistency를 시행한다. 일치하는 대상이 없는 객체는 모든 객체와 유사성 점수가 낮고 여러 대상을 추적하기 위해 중복 제거를 수행하여 일치하는 후보를 필터링 한다.
3. Object Association - feature embedding extractor → bi-directional softmax

객체 feature 임베딩을 기반으로 프레임 전체에서 객체를 추적하는 것은 쉽지 않다. 객체는 매칭 된 후보에서 하나의 대상만 가져야 한다. FP, ID 스위치, 새로 나타난 객체 및 종료된 tracking은 모두 매칭을 불확실하게 한다. 매칭 된 후보를 유지하고 인스턴스 similarity를 측정하는 방법을 포함한 임베딩 space에서 bi-directional matching이 이를 완화할 수 있다.
feature 임베딩 n이 있는 프레임 t에 N개의 검출된 객체가 있다고 가정하고, 과거 x 프레임의 feature임베딩 m과 일치하는 후보 M이 있다고 가정하면, 객체들과 일치하는 후보들 사이의 유사성 f는 양방향 소프트 맥스(bi-softmax, Eq(8))에 의해 얻어진다.

bi-softmax 하에서 높은 점수는 bi-directional consistency를 만족 시키며 매칭 된 두 객체가 임베딩 공간에서 서로 가장 가까운 이웃인 경우이다. instance similarity f는 객체를 간단한 가장 가까운 neighbor search과 직접 연결할 수 있다.
새로 나타난 객체, 사라진 tracking 및 일부 FP 항목과 같은 feature 공간에 target이 없는 객체는 어떤 후보와도 매칭 되어서는 안된다. 이런 객체는 bi-directional consistency를 얻기 어렵기 때문에 매칭 점수가 낮은데 bi-softmax는 이 문제를 직접 해결할 수 있다. 새로 detection 된 객체의 탐지 신뢰도가 높으면 새 tracking을 시작할 수 있다. 이러한 매칭 되지 않은 객체의 이름을 지정하고 매칭 중인 상태를 유지한다. 이는 배경(background)이 FP의 수를 줄일 수 있다는 것을 보여준다.
대부분의 state-of-the-art detector는 NMS(None Maximum Suppression)에 의한 클래스 내 중복 제거만 수행하기 때문에 동일한 위치에 있는 일부 객체의 카테고리가 다를 수 있다. (대부분의 경우, 이 물체들 중 오직 한 물체만 TP(True Positive)임. 이 프로세스는 객체 호출을 촉진하고 높은 mAP에 기여할 수 있음.) 이 문제를 해결하기 위해 NMS에 의해 클래스 간 중복 제거를 수행한다. NMS의 IoU threshold는 검출 신뢰도가 높은 객체(0.5 이상)의 경우 0.7이고 검출 신뢰도가 낮은 객체(0.5 미만)의 경우 0.3이다.
해당 논문에서는 ResNet-50을 backbone으로 사용한다. key frame에서 128개의 RoI를 train 샘플로 선택하고, positive-negative ratio 1.0의 reference frame에서 256개의 RoI를 대조 대상으로 선택했으며 IoU-balanced 샘플링을 사용하여 RoI를 샘플링했다. 그룹 정규화와 함께 4conv1fc head를 사용하여 feature 임베딩을 추출했다. 임베딩 feature의 채널은 기본적으로 256으로 설정되며 12 ephocs에 대해 총 배치 사이즈 16과 초기 학습 속도 0.02로 모델을 학습했다. 8과 11 에폭 후에 학습률(lr)을 0.1까지 낮췄다.
학습과 inference를 위해 이미지의 original sclae을 사용하며 random horizontal flipping만 사용하여 data augmentation한다. 학습을 위해 ImageNet의 pre-trained 모델을 사용했다.
온라인 joint 객체 탐지 및 추적을 수행할 때 탐지 신뢰도가 0.8보다 높을 경우 새 tracking을 초기화하며 배경은 한 프레임 동안만 유지되며 객체는 동일한 카테고리로 분류된 경우에만 연결할 수 있다.
lightweight embedding extractor 및 residual networks와 함께 Faster R-CNN에 적용하여 QDTrack 모델을 구축하고 MOT, BDD100K, Waymo 및 TAO tracking 벤치 마크에 대해 test를 진행했다.
공정한 비교를 위해 이미지의 긴 면을 무작위로 1088로 사이즈 조정하여 자르고 훈련 및 추론 시간에 가로 세로 비율을 변경하지 않는 MOT17를 따랐다. 다른 데이터 augmentation에는 random horizontal flipping 및 color jittering이 포함된다. (COCO의 pre-trained 모델을 제외하고 추가 데이터를 학습에 사용하지 않음.)
TAO에서는 훈련 중 이미지의 짧은 쪽 크기를 조정하기 위해 640에서 800 사이의 척도를 무작위로 선택했다. 추론 시간에는 영상의 짧은 쪽 크기가 800으로 조정되었다. [8, Achal Dave, Tarasha Khurana, Pavel Tokmakov, Cordelia Schmid, and Deva Ramanan. Tao: A large-scale benchmark for tracking any object. In European Conference on Computer Vision, 2020]의 구현과 일관되게 LVIS pre-trained 모델을 사용했다. 그러나, TAO의 train 비디오에 대해 학습을 진행할 때 과적합 문제를 관찰하여 detection 성능이 손상되었다. 그래서 detection 모델을 동결하고 임베딩 헤드를 미세 조정하여 인스턴스 표현을 추출하였다.
논문을 읽은 후 주관을 가지고 요약, 정리한 글이므로 해당 포스팅에 대한 이의 제기, 다른 의견 제시 등 다양한 지적, 의견은 언제나 대환영입니다!
댓글로 남겨주시면 늦더라도 확인하겠습니다!!!