

딥러닝 기반 Deraining 기법 비교 및 연구 동향, Minji Cho et al., 2021을 읽고 요약한 글입니다.
1. 서론
외부 환경에서 촬영된 영상은 비와 눈과 같은 날씨나 환경의 영향을 받아 영상 내의 객체가 변형되거나 흐려진다. 때문에 정확하게 객체를 검출하기 힘들고 오검출이 빈번하게 발생한다. 이러한 오검출을 줄이기 위해서는 이미지 전처리 과정에서 빗줄기나 눈과 같은 날씨 및 환경에 의해 손상된 영상을 선명하게 복원을 한 후에 객체를 검출해야 한다.
손상된 영상을 복원하는 deraining 기법으로 딥러닝 네트워크로 빗줄기를 검출하여 제거한 영역의 배경을 복원하는 방법인 Deep Detail Network(DDN)가 제안되었다. 해당 방법은 입력에서 출력까지 학습 과정을 경량화하기 위해 잔차를 구하여 CNN(Convolutional Neural Network)을 설계하고 빗줄기를 없애면서 제거한 부분의 영역이 흐려지는 것을 보완하기 위해 마지막 convolution layer의 출력에 입력 영상을 더한 negative-매핑 방식을 도입하였다. 이런 방법은 ResNet만 적용했을 때보다 영상의 품질을 높일 수 있지만 굵은 빗줄기나 큰 빗방울을 처리하는데 한계가 있다.
이러한 문제를 해결하기 위해 GAN(Generative Adversarial network)을 사용한 Attentive GAN과 입력 영상을 다양한 크기 비율로 나눠 여러 단계로 처리하는 Multi-scale 네트워크인 LPNet, Visual Attention 개념을 적용한 MSPFN, MPRNet 등과 같은 deraining 기법들이 연구되어 오고 있다.
해당 연구에서는 이러한 대표적인 딥러닝 기반 단일 영상 deraining 알고리즘 기법들을 비교하고 적절한 알고리즘을 채택하는 것이 목적이다.
2. 딥러닝 기반의 Deraining 기법 비교 및 동향
1) Attentive GAN
GAN의 분류 네트워크는 생성 네트워크에서 생성된 영상을 정답과 비교해 생성된 영상이 진짜인지 가짜인지 판단을 하고 그 지표로 loss 값을 출력한다. 이 loss 값이 다음 epoch의 생성 단계에서 활용하는 것을 반복한다.
Attentive GAN은 입력 영상에서 특징을 추출할 때 사용하는 ResNet의 residual 블록에 long short-term memory와 합성곱 레이어를 추가한 것이다. 매 스텝마다 합성곱 레이어는 출력으로 영상의 전체 영역에서 빗방울이 있는 정도를 0~1 범위의 수치로 정규화한 2차원 행렬의 attention map을 생성한다.
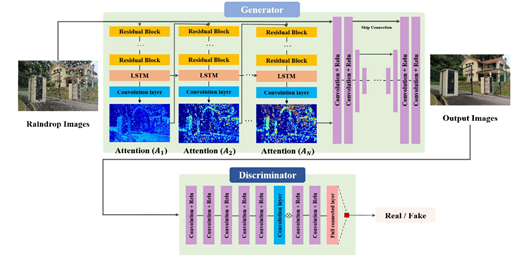
스텝을 거듭할수록 빗줄기와 빗줄기로 인해 손상된 배경의 영역이 더 디테일하게 나타나며 이렇게 생성된 attention map은 생성 네트워크와 분류 네트워크의 학습에 사용된다. 이 결과는 DDN을 적용하였을 때 보다 빗줄기로 인해 손상된 배경 복원에 더 뛰어난 결과를 보였다.
2) LPNet (Lightweight Pyramid Network)

단계가 높아질수록 크기 비율을 키우고 그에 따라 해상도가 줄어든 영상들을 쌓은 것을 영상 피라미드라고 한다. 이때 크기 비율을 조절하는 과정에서 가우시안 필터가 사용된 피라미드를 가우시안 피라미드라고 부른다. 또, 가우시안 피라미드에 각 단계의 영상들의 차이를 구하고 라플라시안 필터로 처리해 경계선 이미지를 쌓은 것을 라플라시안 피라미드라고 한다.

위 그림의 (a)와 같이 입력된 빗줄기 이미지들은 분해되어 라플라시안 피라미드로 나타난다. 라플라시안 피라미드의 각 단계는 재귀적 잔차 하위 네트워크의 입력이 된다. 라플라시안 피라미드의 각 단계에 해당되는 경계선 이미지가 입력되어 빗줄기에 해당하는 경계선 영역이 지워진 채로 출력이 된다. 이 출력은 이전 단계까지 축적된 결과 영상에 더해져서 빗줄기가 제거된 영상의 가우시안 피라미드가 만들어진다.
LPNet은 피라미드 구조를 적용하여 낮은 파라미터 수와 높은 연산 속도라는 장점을 가지고 있지만 피라미드의 각 단계의 하위 네트워크들이 개별적으로 학습을 수행하여 출력을 병합하기 때문에 서로 다른 크기 비율 간의 연관 관계에 대해서는 학습을 하지 않는다는 한계가 있다.
3) MSPFN (Multi-Scale Progressive Fusion Network)
MSPFN은 LPNet과 같은 기존 방법론들이 다양한 크기 비율을 적용하고 있음에도 구조적 한계로 인해 여러 정보들 간의 상관관계가 학습에 이용되지 못하는 문제를 해결하기 위해 개별 단들이 서로 학습을 공유하는 새로운 구조로 제안되었다. LPNet에서 사용한 피라미드 구조는 유지하되 하위 네트워크 단을 변경하였으며 아래 그림은 피라미드 구조를 3단계로 설정했을 때의 MSPFN의 구조를 나타낸 그림이다.

MSPFN은 정보들의 상관관계를 활용하기 위해 세 가지 모듈을 사용한다. 첫 번째 모듈인 Coarse Fusion Module(CFM)에서는 영상에서 빗방울을 추측할 때 학습 영상에서 얻은 특징 정보로 그 영역을 찾을 수 있도록 서로 다른 크기 비율에서의 정보들의 상관관계를 구한다. 이는 서로 다른 종류의 빗방울들을 characterize하는데 기여한다. 두 번째 모듈인 Fine Fusion Module(FFM)은 CFM에서 뽑은 정보들의 관계를 정제하는 작업을 수행한다. FFM의 Channel Attention Unit(CAU)에서 정보들 간의 관계를 중요도에 따라 나열을 하고 정체를 한다. 마지막 모듈인 reconstruction 모듈에서는 CFM와 FFM을 거쳐 얻은 빗줄기에 대한 특징 정보를 토대로 잔차 빗줄기 영상을 추정한다. 융합된 빗줄기 정보들을 토대로 reconstruction 모듈 단에서 빗줄기 재현 영상이 만들어진다. 빗줄기가 제거된 영상은 원본 영상과 재현 영상 간에 차이(subtraction)를 적용하여 획득하게 된다.
4) MPRNet (Multi-Stage Progressive Image Restoration Network)
MPRNet은 초기 단계에서 encoder-decoder 구조를 사용하여 원본보다 작은 다중 크기 비율의 문맥 정보를 학습하고 마지막 단계에서는 원본 해상도 영상을 받아 공간적인 디테일을 유지한다.
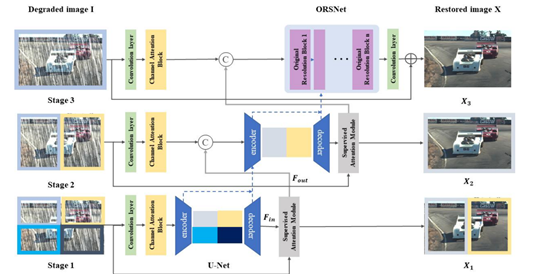
MPRNet의 구조를 나타내고 있는 위 그림에서 stage 1일 때 원본 영상 1을 1/4 크기 비율로 나누어 처리하고 마지막 단계에서는 원본 영상을 그대로 입력으로 사용하는 것을 볼 수 있다.
MPRNet은 한 단계에서 다음 단계로 넘어갈 때 Supervised Attention Module(SAM)이라는 모듈이 이전 단계의 예측을 토대로 만든 attention map과 영상을 기반으로 특징 정보들을 정제하여 넘긴다. 이러한 SAM 구조와 작동방식은 아래 그림에 나타나 있다.
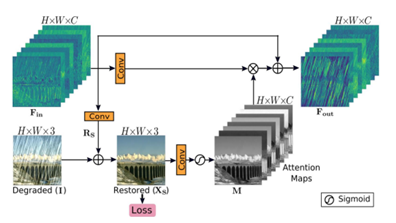
Channel Attention Block(CAB)과 encoder-decoder 단의 U-Net을 통해 추출된 Input으로 잔차 빗줄기 영상을 얻는다. 원본 영상에 이 잔차 빗줄기 영상을 더해 복원 예측 영상을 얻고 영상과 복원 예측 영상 사이의 loss를 구한다. 잔차 빗줄기 영상에 시그모이드 함수를 적용하여 attention map을 얻으며 이 attention map은 input을 보정하여 attention 정보를 기반으로 보강된 특징 표현(augmented representation)인 Output을 생성하는데 사용된다. 이렇게 생성된 Output은 다음 단계의 입력단에 더해진다. 원본 영상에 Output을 더해 Original Resolution Block(ORB)으로 이루어진 ORSNet에 입력으로 넣어 최종 복원 영상을 구하게 된다.
결과적으로 MPRNet은 MSPFN에 비해 오류를 20% 줄이고 파라미터 수를 3.7배 줄여 연산 속도를 향상시켰다.
3. 네트워크 결과 성능 비교 및 결론
이슬비 데이터셋으로 학습을 진행한 Attentive GAN과 LPNet은 이슬비 테스트셋에 대해서 높은 성능을 보이지만 장대비 테스트셋에 대해서는 낮은 성능을 보였다. 장대비 데이터셋으로 학습을 진행한 MSPFN과 MPRNet은 장대비 테스트셋에 대해 좋은 성능을 보이지만 이외의 테스트셋에서는 비교적 낮은 성능을 보였다.

아래 그림과 같이 실제 맑은 날의 영상이 없는 실생활 데이터셋에 대한 결과로 객체 검출 네트워크로 결과를 비교하였다. 검출 정확도 측면에서 큰 차이는 없지만 손상된 이미지에서 검출하지 못한 객체를 인식하는 결과를 얻었음을 알 수 있다.

앞서 비교한 4가지 deraining 기법들이 지도 학습을 기반으로 하기 때문에 정답 영상(Ground Truth, GT)을 필요로 한다. 때문에 정답 영상(GT)을 구할 수 없는 실생활 영상에서는 화질이 저하되는 문제가 발생하는 것을 볼 수 있었다.
논문을 읽은 후 주관을 가지고 요약, 정리한 글이므로 해당 포스팅에 대한 이의 제기, 다른 의견 제시 등 다양한 지적, 의견은 언제나 대환영입니다!
댓글로 남겨주시면 늦더라도 확인하겠습니다!!!