
빅데이터란?
빅데이터란 디지털 환경에서 발생하는 대량(수십 테라바이트)의 데이터를 말한다.
데이터 그 자체의 의미도 있지만 기존 데이터베이스 관리 도구의 능력을 넘어 데이터에서 가치를 추출하고 결과를 분석하는 기술을 의미하기도 한다.

이러한 빅데이터를 처리하기 위한 방법으로는 병렬 컴퓨팅 또는 분산 컴퓨팅의 사용과 클러스터 컴퓨팅의 사용 등이 있다.
분산환경의 빅데이터 처리
➡ 병렬 컴퓨팅(Parallel Computing)
한 대의 컴퓨터 안에서 CPU 코어를 여러 개 사용해서 한 대의 컴퓨터가 처리하는 데이터의 총량과 처리속도를 증가시키는 것이다. 이와 관련해서 멀티 프로세스, 멀티 스레드 개념이 중요하게 다뤄진다.
- 멀티 프로세스
멀티 프로세스는 2개 이상의 프로세스를 사용 것이다. 프로세스는 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램을 의미하며 스케줄링의 대상이 되는 작업(task)이라는 용어로도 사용된다. 프로세스 관리는 OS에서 한다.
- 멀티 스레드
멀티 스레드는 2개 이상의 스레드를 사용하는 것이다. 스레 드는 어떤 프로그램, 특히 프로세스 내에서 실행되는 흐름의 단위로 일반적으로 한 프로그램은 하나의 스레드를 가진다.
➡ 분산 컴퓨팅(Distributed Computing)
분산 컴퓨팅은 여러 대의 컴퓨터가 네트워크로 연결된 상황을 전제로 하며 P2P(Peer to Peer), HTTP, Network와 같은 네트워크 용어들이 중요하게 다뤄진다.
➡ 클러스터 컴퓨팅
클러스터는 여러 대의 컴퓨터들이 연걸된 것이다. 이 때 컴퓨터를 어떻게 연결하고 자원을 관리할 것인지에 따라 많은 클러스터 관련 기술이 알려져 있으며 대표적인 기술로는 병렬 컴퓨팅, 분산 컴퓨팅, 클라우드 컴퓨팅이 있다.
클러스터 컴퓨팅은 여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합이다. 이는 노드와 관리자로 구성되어 있다.클러스터 노드는 프로세싱 자원을 제공하는 시스템이며 클러스터 관리자는 노드를 서로 연결해 단일 시스템처럼 보이게 만드는 로직을 제공한다.
클러스터 컴퓨팅을 전제로 설계된 시스템
- 하둡

하둡은 대용량 데이터를 분산 처리할 수 있는 자바 기반의 오픈소스 프레임워크이다.
구글의 분산 파일 시스템이 나오면서 기술적 우위를 공고히 하게 되지만 GFS는 구글에서 공개를 하지 않았고 아파치 재단(Apache Foundation)에서는 구글의 맵리듀스 및 GFS에 해당하는 HDFS(Hadoop File system)를 포함하는 하둡(Hadoop)이라는 오픈소스 프로젝트를 2006년 4월에 발표했다.
하둡은 오픈소스라는 강점을 내세워 대략의 데이터 처리를 지원하는 사실상의 표준 프레임워크로 군림하게 되었다.
맵리듀스의 문제이기도 한 하둡의 약점은 map 함수가 모두 종료되어야 reduce 함수가 실행된다는 성능 손실이다.
이러한 약점이 하둡으로 실시간 서비스를 제공하는 것을 불가능하게 했으며 하둡은 빅데이터 기반의 배치성 통계작업에만 두입되고 있다.
- 스파크

2009년에 처음 발표된 스파크는 MapRedue 기능에서 map 함수가 전부 종료되지 않더라도 Map의 결과를 스트리밍 하는 방식이다.

위의 그림에서 map 함수의 결과가 디스크에 저장되고, 그걸 reduce 함수가 다시 읽어와야 하는데 이는 성능 상의 손실이 크다. 하지만 스파크는 데이터를 메모리에 적재하여 사용하는 인메모리 데이터 엔진을 통해 이런 손실을 극복하며 스파크의 성능이 하둡의 10배에 달하게 된다.
또, 스파크는 자바(Java), 스칼라(Scala), 파이썬(Python), R 프로그래밍 언어를 위한 네이티브 바인딩을 제공하므로 다양한 언어가 필요한 환경에서 쉽고 빠르게 스파크와 연동할 수 있다. 때문에 서버 쪽에서 행해지는 처리에서는 자바나 스칼라를 이용해 스파크를 구성하고, 데이터 분석가들은 친숙한 파이썬을 이용해 데이터를 처리하는 경우가 많다.
또한 데이터 분석을 위해 SQL, 스트리밍 데이터, 머신러닝, 그래프 프로세싱을 추가로 지원하며 csv 파일을 pandas로 읽어 DataFrame으로 분석하는 것 마냥 로컬 컴퓨터에는 저장하기 힘든 큰 데이터를 DataFrame으로 처리할 수 있다는 장점이 있다.
하지만 무조건 스파크가 하둡보다 좋은 것은 아니다.
하둡은 스파크가 제공하지 않는 HDFS와 같은 분산 파일 시스템을 제공하고 있으며 스파크 자체가 하둡 기반으로 구동하는 것을 목적으로 만들어졌기 때문에, 꼭 하둡이 필요하진 않지만 하둡 기반으로 돌아가는 것이 좋다.
맵리듀스
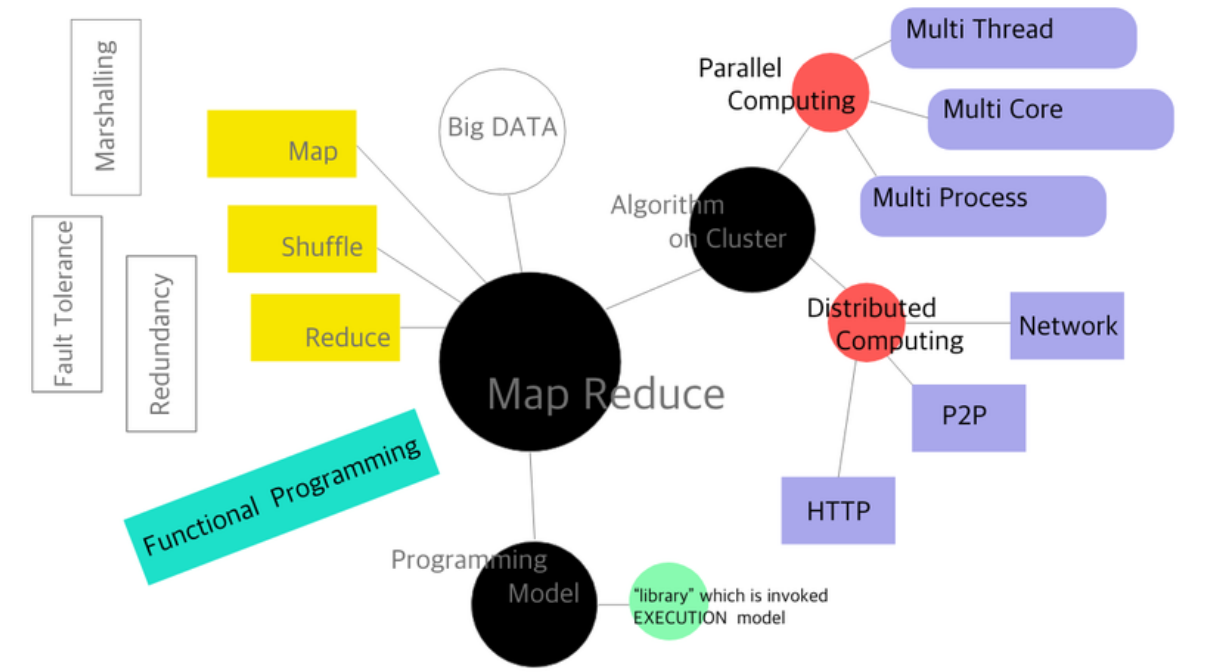
하둡, 스파크 등의 빅데이터를 다루는 솔루션들의 근간이 되는 프로그래밍 모델은 맵리듀스(Mapreduce)이다.
맵리듀스는 하나의 컴퓨터에서 하던 작업을 여러 개의 컴퓨터에서 처리하도록 분산시키는 프로그래밍 모델이다. 간단히 말해 많은 것을 잘게 나눠 각각 처리한 후 처리한 것들을 모아 통합 결과물을 내는 것이다.
이를 데이터분석의 Split-Apply-Combine Strategy라고 하는데, 이러한 Split-Apply-Combine Strategy는 파이썬과 SQL, R 등 다양한 곳에서 사용되고 있으며 맵리듀스 또한 마찬가지이다.
맵리듀스는 크게 map() 함수와 reduce() 함수로 구성되어 있다.
map() 함수는 Split 된 부분 데이터를 가져와 특별한 조작을 가하는 Apply 역할을 하는 함수이다.
reduce() 함수는 map() 함수가 만들어낸 결과물들을 특정 기준에 따라 다시 모아내는 Combine 역할을 하는 함수이다.
맵리듀스의 프로그래밍 모델 개요

map 함수는 in_key와 in_value를 인자로 가진다.
in_key란 바로 split의 결과로 생긴 partitioning 키 값인데, 이 키 값은 최종 output에는 반영되지 않는다.
map 함수는 split 된 데이터를 가져다 out_key와 intermediate_value의 리스트로 변환하며 out_key는 map 함수가 결과물을 구분하는 기준 키 값이 된다.
reduce 함수의 입력은 여러 map 함수의 intermediate_value들을 out_key 별로 구분해 리스트업 한 것을 input으로 한다.
reduce 함수는 out_key 기준으로 sum을 하고 reduce 함수인 일꾼은 최종적으로 out_value의 리스트를 출력한다.
reduce 함수는 모든 map 함수가 중간 결과를 반환할 때 까지 기다렸다가 한꺼번에 그룹핑한 결과가 나올 때 까지 기다린다. 이는 해당 시스템의 약점이라고 할 수 있다.

위 그림은 MapReduce의 실행(Execution)모델이다.
M이 Input을 입력받아 Intermediate로 출력하고 R이 Intermediate를 out_key 기준으로 Grouping한 것을 Input으로 입력받아 Output을 출력하는 구조로 진행된다.
reduce 함수가 대기라는 약점이 있지만 위 그림을 통해 map 함수 뿐만 아니라 reduece 함수도 병렬수행이 가능하다는 것을 알 수 있다.