Contrastive Learning이란? (feat. Contrastive Loss, Self-supervised learning)
⏹ Contrastive learning이란?
Contrastive learning이란 self-supervised learning(자기 주도 학습)의 주된 학습 방법으로 데이터들 간의 특정한 기준에 의해 유사도를 측정하기 위해 샘플 데이터 간의 비교를 통해 학습된 표현 공간(representation space) 상에서 비슷한 데이터는 가깝게, 다른 데이터는 멀게 존재하도록 표현 공간(representation space) 을 학습하는 것이다.
➡ Self-supervised learning
비지도학습의 한 분야에 속하는 방법으로 스스로 supervision을 주는 방법으로 라벨링이 되어 있지 않은 데이터로 학습을 진행한다.
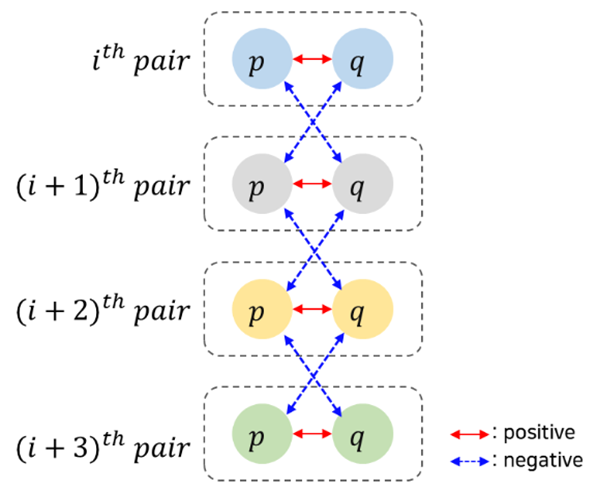
positive pair와 negative pair로 구성되며 입력쌍에 대해 유사도를 라벨로 판별 모델 학습을 한다. 하나의 sample에서 두가지의 view가 생성된다고 했을 때, 같은 이미지에서 나온 pair는 positive pair이며 다른 이미지끼리는 무조건 negative pair가 된다.
이때 유사함의 여부는 데이터 자체로부터 정의될 수 있으며 이는 곧 self-supervised learning이 가능하다는 것을 의미한다.
때문에 라벨이 없어 보다 일반적인 feature representation이 가능하며 새로운 class가 들어와도 대응이 가능하다는 장점이 있다. 따라서 classification 등 downstream task에 대해 네트워크를 파인 튜닝 시키는 방향으로 활용하기도 한다.
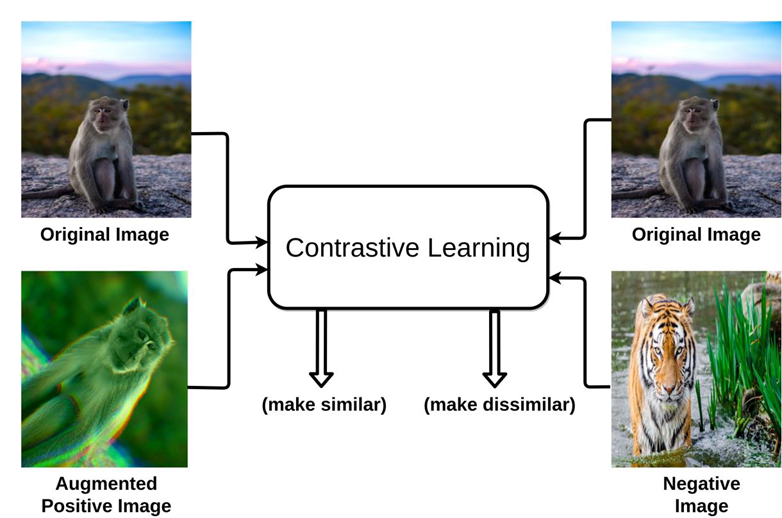
Contrastive learning은 같은 이미지에 서로 다른 augmentation을 가한 뒤 두 positive pair의 feature representation이 거리를 좁히도록(유사해지도록), 다른 이미지에 서로 다른 augmentation을 가한 뒤 두 negative pair의 feature representation은 거리를 멀리 띄워 놓도록 학습을 진행한다.
학습 불안정 이슈를 극복하기 위해 momentum을 적용하여 성능을 끌어올린 논문(MoCo)도 있으니 함께 보면 좋다.
이후 google research와 brain team의 A Simple Framework for Contrastive Learning of Visual Representations 논문(SimCLR)이 공개되었다. 해당 논문에서는 contrastive laerning 기반, architecture나 memory bank없이 학습 시킬 수 있는 아이디어 제안했으며, 적절한 data augmentation 사용, learnable nonlinear transformation, contrasitve loss를 제안했다.
이외에도 contrastive learning을 기반으로 한 논문은 아래 링크에 있으니 관심 있으면 꼭! 보는 것을 추천한다.
→ contrastive learning을 기반으로 한 논문 정리 링크

Data augmentation을 통해 input을 생성하면 입력 이미지 쌍으로 feature extraction을 진행하며(feature extraction 부분을 feature encoder e로 칭한다) representations을 생성한다.
이후 projection head(MLP 구조)에서 encoder에서 얻은 특징 벡터(v)를 더 작은 차원으로 줄여주는 작업을 수행한다. 2048 dimension의 Feature vector(v)를 128 dimension의 metric embedding(z)으로 projection 해주는 용도로 projection head가 사용되는 것이다.
positive pair의 embedding은 가깝게, negative pair의 embedding은 멀게 하도록 하는 objective를 직접적으로 수행하며 이를 Contrastive Loss라고 한다.
➡ Contrastive Loss
contrastive loss는 positive pair loss와 negative pair loss를 합친 것이다.
같은 이미지(같은 클래스)일 경우 라벨이 1, 다른 이미지(다른 클래스)일 경우 라벨이 0이며 이미지에서 cnn을 이용해 임베딩을 추출하고 임베딩 간의 거리를 이용해 loss값을 구한다.
- positive pair

- negative pair loss


- contrastive loss

라벨이 0인 경우(다른 이미지일 경우) 위의 식에서 (1-y)부분이 0이 된다.
즉, contrastive loss를 통해 학습하는 것은 두 데이터가 negative pair일 때 margin 이상의 거리를 갖도록 학습하는 것이다. contrastive loss를 이용해 deep metric learning을 하게 되면 비슷한 이미지끼리는 embedding 거리가 가깝도록, 다른 이미지끼리는 embedding 거리가 멀어지도록 하여 유사한 데이터들끼리 clustering될 것이다.
따라서 constrastive loss는 contrastive learning의 한 종류이다.
참고 링크 및 문헌 :
https://www.v7labs.com/blog/contrastive-learning-guide
https://towardsdatascience.com/understanding-contrastive-learning-d5b19fd96607